Autor: Omar Aurelio Walid Llorente
Tutor: Tomás Pedro de Miguel Moro
Fecha: 25 de julio 2003
| Presidente | : | D. Tomás Pedro de Miguel Moro | ||||||||||
0
En un sistema académico en el que las necesidades de software son cada día más cambiantes mientras que los recursos disponibles permanecen estables, resulta necesario encontrar una solución que permita gestionar de forma automática y desatendida un gran número de computadores, sus redes, sus servicios y sus usuarios. Este proyecto pretende ofrecer una solución general y demostrar su viabilidad mediante su aplicación a los Laboratorios Docentes del Departamento de Ingeniería de Sistemas Telemáticos (DIT) de la Escuela Superior de Ingenieros de Telecomunicación (ETSIT) de la Universidad Politécnica de Madrid (UPM).
Abstract:
In academic systems where the software necessities are changing day by day, while the available resources are stable, is becoming critical to find a solution which allows the automatic and unattended administration of a big number of computers, their data networks, their services and their users. This technical report tries to offer a general solution and demonstrate its viability at the Grade Laboratories at Technical University of Madrid's Telematics Department.
Administración cero, Administración centralizada, Instalación automática, Instalación desatendida, Administración de sistemas, Administración de redes, Regeneración de particiones, Arranque de red, PXE, DHCP.
Key Words:
Zero Administration, Centralized Administration, Automatic installation, Unattended installation, Systems administration, Networks administration, Partition regeneration, Network boot, PXE, DHCP.
Ya en la década de los 80, el arranque remoto de ordenadores era algo muy utilizado en el mundo de los ordenadores con sistema operativo UNIX, sin embargo, en el mundo del ordenador personal, este sistema de arranque era relativamente desconocido hasta la década de los 90.
En esta época, empezaron a surgir los primeros proyectos que permitían a un PC arrancar desde un sistema servidor a través de la red, valiéndose del programa almacenado en una pequeña memoria EEPROM que se alojaba en su adaptador de red (véase (3) para más información sobre los esfuerzos que el DIT realizó en este campo en el pasado). Esto permitió que los laboratorios basados en la utilización de ordenadores con este tipo de facilidades tuviesen un entorno repetible y mucho más flexible de lo habitual, pero este sistema estaba limitado a un único sistema operativo, que por aquellas fechas era de los pocos disponibles para ordenadores PC, el MS-DOS. Para realizar la configuración del dispositivo de red se habían desarrollado dos protocolos: RARP (Reverse ARP) y BOOTP (Protocolo de Arranque), mientras que para realizar las transferencias de imágenes se utilizaba muy comúnmente TFTP (siglas de Trivial File Transfer Protocol) que era un subconjunto del protocolo FTP y funcionaba sobre UDP/IP.
A mediados de los 90, los sistemas operativos empezaron a ofrecer utilidades basadas en el procesador local, a crear entornos gráficos para el usuario y a requerir más espacio de almacenamiento, tanto de tipo permanente como de tipo temporal, lo que hizo que las utilidades y aplicaciones que hasta entonces proporcionaban la posibilidad de efectuar el arranque del sistema operativo desde la red dejaran de ser útiles. Surgieron entonces otros proyectos que pretendieron resolver estas necesidades de forma muy similar a como se había hecho hasta entonces, utilizando los mismos protocolos pero ampliando sus capacidades (véase (9,8,7)) basándose en el código proporcionado por los fabricantes para el uso de los adaptadores de red que había disponibles en sistemas operativos de propósito general, como eran MS-DOS o Free-BSD.
A finales de los 90, surgieron nuevas especificaciones que cambiaron totalmente la definición de los protocolos e interfaces utilizados para el acceso a la red y a los recursos locales y remotos de los ordenadores PC que pretendían iniciar sus sistemas operativos desde la red, así surgieron el PXE (11) (siglas de Preboot eXecution Environment) y el DHCP (12) (acrónimo de Dynamic Host Configuration Protocol y evolución del BOOTP).
En el Departamento de Ingeniería de Sistemas Telemáticos (DIT), siempre ha habido un gran interés en la creación de facilidades y procedimientos que permitiesen realizar un mantenimiento automático de los puestos de laboratorio en los que los alumnos realizan sus prácticas, y éste ha sido el motor de cambio que ha permitido conseguir algo que, hoy por hoy, se aproxima mucho a esa meta.
Las necesidades que han impulsado este proyecto son aquellas que resultan de la implantación de redes con alta densidad de ordenadores. El abaratamiento de costes y las economías de escala de los ordenadores de tipo PC (siglas originales de Personal Computer) han permitido la ampliación de las redes de ordenadores de forma espectacular en los últimos años, permitiendo crear salas de computadores mucho más grandes. Con ello, y de manera indefectible, ha llegado la necesidad de gestionarlos de la manera más automática posible.
Como es bien sabido, cabe remarcar dos tipos de instalaciones de ordenadores según su función en la red. Los primeros, llamados servidores, tienen una o varias funciones concretas que proporcionan servicios que necesitan otros ordenadores y que éstos consiguen generalmente a través de protocolos específicos de red. Los segundos, que llamaremos clientes a lo largo de este proyecto, son aquellos que son utilizados principalmente por los usuarios para acceder a los servicios telemáticos que los servidores ofrecen a través de la red, así como para realizar tareas (normalmente de carácter ofimático) en el entorno local.
Son ejemplos comunes para el caso del entorno de los servidores, las granjas de ordenadores y las salas de computación, mientras que para el caso de los ordenadores de tipo cliente, lo son las salas de acceso a Internet que proliferan en universidades, colegios y lugares de ocio (cibercafés).
Los dos tipos de instalaciones requieren un tratamiento diferente desde el punto de vista de la administración del sistema. En el caso del ordenador de tipo cliente, el procedimiento tradicional de gestión del ordenador comienza con la instalación manual de un sistema operativo, continúa con la instalación de las aplicaciones y finaliza cuando el ordenador finalmente es conectado a su red de acceso y empieza a ser utilizado por el usuario final. Esta instalación del sistema completo es uno de los procedimientos que el sistema de gestión automatizada pretende resolver y en el cual entraremos en profundidad más adelante.
Una vez que el ordenador está instalado y funcionando, podríamos pensar que este proceso de instalación será suficiente para que el ordenador en cuestión dé servicio durante un período largo de tiempo, sin embargo, la estabilidad de los programas que se ejecutan en él no es tan alta como la del sistema físico en el que se apoyan, siendo necesario regenerar la instalación del sistema cada cierto número de horas de trabajo. Esto es especialmente cierto en entornos en los que es necesario utilizar aplicaciones de programación que pueden afectar al funcionamiento del propio sistema operativo, en entornos en los que el trabajo requiere partir de una instalación específica del sistema o en aquellos en que los ordenadores están expuestos al ataque externo en el amplio sentido de la palabra.
El número de horas que un sistema operativo está en perfectas condiciones de uso, es muy difícil de determinar empíricamente debido a la gran dependencia con el tipo de usuario que utilice el computador, así como del tipo de sistema operativo instalado, su conexión a Internet y de la posibilidad de que el usuario instale sus propios programas en el sistema. También tienen una influencia cada vez mayor los programas de distribución automática que aprovechan fallos de seguridad del sistema, como son los virus, los troyanos, el spyware, las puertas traseras, etc. Por todo esto, necesitamos que nuestro sistema de gestión de ordenadores de tipo cliente permita la reinstalación del sistema cuantas veces sea necesario, en el menor tiempo posible y con garantía total de que el sistema, una vez regenerado, está dispuesto para el funcionamiento, tal y como lo estaba el primer día.
El ordenador de tipo servidor, al tener otros ordenadores que dependen de sus servicios y se conectan a él a través de la red, tiene un perfil diferente y más crítico. La problemática también es otra y viene derivada de que la instalación y administración de servidores requiere mucho más tiempo y esfuerzo que la instalación de ordenadores de tipo cliente. Cuando tenemos grandes redes de ordenadores de tipo servidor, gran parte del sistema operativo suele ser común entre ellos, mientras que éstos se diferencian entre sí en los servicios que ofrecen a la red. El que tengan una gran parte común, permite racionalizar el esfuerzo para la instalación del sistema operativo mediante la utilización de sistemas de instalación automática que se suelen proporcionar a nivel de fabricante, pero aún queda la parte de configuración de los servicios que un servidor concreto es capaz de implementar y que suele ser la que más tiempo de administración consume. Aunque la configuración del mismo servicio en servidores diferentes suele tener una parte común muy importante, esta parte común es dependiente de parámetros generales de nuestra red y de nuestro servicio que no suelen ser los propuestos por el sistema de instalación automática del sistema operativo. Aquí surge, por tanto, una nueva necesidad que hemos de acometer y que también será motivo de explicación en los próximos capítulos.
Hoy por hoy, hay una gran cantidad de sistemas operativos disponibles para la computadora personal más común del planeta, el ordenador PC. Si bien, todas ellos ofrecen características diferentes de funcionamiento y habilidades muy diversas, todos se basan en una plataforma hardware común, el IBM PC que ha ido evolucionando a gran velocidad desde que los sistemas operativos han empezado a utilizar entornos gráficos y sistemas de procesamiento de datos mucho más potentes.
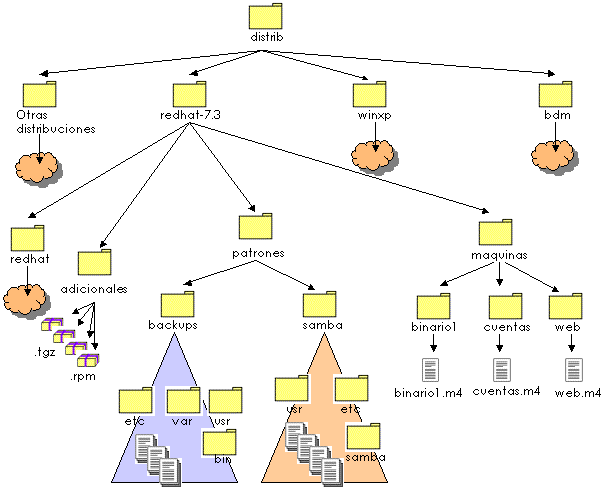
En el marco de este proyecto, sólo se ha atendido a las necesidades de utilización de los laboratorios del DIT, por lo que las necesidades se han circunscrito a la implementación de las facilidades necesarias para los sistemas operativos basados en Microsoft Windows y en GNU/Linux.
Dentro de los entornos Windows, se ha dado soporte a diferentes sistemas (desde el Windows 98 al Windows XP Professional, pasando por el Windows NT 4.0), sin embargo, en este documento sólo se mencionarán las tareas realizadas para la automatización de la gestión del entorno más moderno de todos ellos (el Windows XP Professional).
Dentro de los entornos GNU/Linux, hay una gran variedad de distribuciones que permiten instalar, configurar y gestionar tanto servidores como máquinas de usuario, pero en este proyecto nos centraremos en la distribución RedHat 7.3, aunque se podrían haber utilizado otras distribuciones, de las miles que hay hoy en día disponibles. Las razones principales de esta elección son la estabilidad y las facilidades de instalación y configuración, así como por las compilaciones del núcleo del sistema operativo Linux que suelen dar soporte a gran variedad de dispositivos hardware, incluyendo para éstos las mejoras más recientes.
En versiones anteriores de este proyecto, se han utilizado también otros sistemas operativos que hoy en día han caído en desuso. Así, podemos mencionar que mediante Boots (3) se podía hacer arrancar una imagen de MS-DOS de hasta 2.8MB que contenía el código necesario para montar como discos locales los servidores de red por NFS (Network File System (26)) en la época de los procesadores Intel 80286 y 80386. Más adelante, se utilizaba tanto Etherboot (8) como Netboot (7) para iniciar imágenes de red que permitían transferir a través de la red el núcleo GNU/Linux, esto ya se hacía con CPUs del tipo Intel 80486 y los primeros Pentium que salieron al mercado.
El objetivo de este proyecto, en pocas palabras, viene a ser la implementación de un sistema centralizado que sea capaz de realizar el mantenimiento automático de los sistemas operativos de un gran número de ordenadores, tanto de servidores de red como de máquinas de usuario o máquinas cliente. Para ello, el proyecto ha de hacer uso de las herramientas disponibles que, si bien, tienen una alta utilidad, ninguna de ellas es capaz de llevar a cabo el objetivo de este trabajo completo. Por eso, este proyecto se ha realizado con la idea de agrupar, aprovechar y aumentar los esfuerzos que muchos otros han desarrollado previamente y así conseguir llevar a la realidad el objetivo fundamental.
En esta sección, realizamos un análisis de las aplicaciones que se han puesto a disposición de los distintos sistemas operativos (GNU/Linux y Microsoft Windows XP Professional) utilizados por el DIT en sus laboratorios, para la simplificación de las tareas de administración de éstos y veremos que aunque la mayoría tienen mucha utilidad en su área de aplicación, ni tienen un entorno común de gestión ni proveen todas las facilidades requeridas, por lo que habrá que unificar su administración y uso para llevar a cabo el proyecto.
Si nos planteamos el realizar un sistema de administración centralizada para sistemas GNU/Linux, estará bien que empezamos a analizar las utilidades disponibles para la gestión de ordenadores. Dada su naturaleza abierta, cabe decir que las propias características de este sistema operativo crean un caldo de cultivo de soluciones que ha resultado ser muy próspero en los últimos años en todos los sentidos. También cabe comentar que esta misma característica ha promovido el desarrollo de diversas y muy diferentes distribuciones de GNU/Linux, cada una de ellas con sus propias ventajas e inconvenientes pero también con un gran denominador común: todas usan Linux (17) como núcleo del sistema y todas aprovechan en mayor o menor medida la gran cantidad de herramientas proporcionadas por el proyecto GNU (16).
Así, mediante la funcionalidad de la herramienta Kickstart (13)de la distribución RedHat (22) podemos realizar la instalación del sistema operativo, también podemos elegir las aplicaciones que queramos que tenga instaladas -dentro de las que vienen compiladas con la propia distribución- y realizar una configuración básica de los dispositivos hardware basándonos en la cantidad de memoria, tipo de CPU, pantalla, teclado, disco duro o tarjeta de red. Esta aplicación concreta, si bien resulta muy útil dado que permite clonar instalaciones desatendidas sin demasiado esfuerzo, no está pensada para la configuración del software del servidor ni para la gestión de las actualizaciones software del mismo. Hay proyectos que intentan mejorar la funcionalidad de Kickstart (que realmente es una extensión del instalador de RedHat -anaconda- para instalaciones desatendidas), en concreto, uno de los que cabe mencionar aquí, por estar claramente relacionado, es Kickstart Tools (55).
También hay que mencionar Replicator (1) y FAI (2) que tienen muchas cosas en común con RedHat Kickstart y que también tienen sus mismas limitaciones. Ambos proyectos están orientados a la distribución Debian GNU/Linux. Replicator está más orientado a gestionar la instalación desatendida de una máquina basándose en el patrón de la instalación de otra y así realizar un clon de la misma. FAI es un proyecto que pretende la automatización completa de la instalación de un servidor y puede ser un candidato muy interesante a considerar para la instalación de máquinas de forma desatendida, pero sin basarse en otras previamente instaladas.
Una de las partes más importantes para la gestión de la automatización de las instalaciones es la posibilidad de gestionar el arranque desde los distintos medios disponibles, como son la disquetera, el lector de CD-ROM, la red o el propio disco duro. Por tanto, será muy conveniente que el sistema de gestión de arranque sea capaz de utilizar el medio que hayamos elegido para la instalación. Así, podemos mencionar la utilidad del sistema de arranque GRUB (29) que permite gestionar el arranque del núcleo de Linux tanto desde todos los medios mencionados, además de ser capaz de cargar su configuración a través de la red utilizando una imagen compatible PXE configurable también a través de la red. Otro de los sistemas más populares para el arranque de un sistema PC es LILO(42), que últimamente ha introducido mejoras para el arranque de discos virtuales y ofrece diferentes facilidades.
En el entorno de gestión de arranque, una de las novedades que han proporcionado más potencia al sistema de arranque ha sido el proyecto Syslinux(9), un gestor de arranque que permite configurar el inicio del sistema desde disquete (syslinux), CD-ROM (Isolinux+Memdisk) o desde una imagen PXE traída por la red (Pxelinux). Este sistema tiene la ventaja, frente a sus competidores en la gestión del arranque por red, de que no necesita tener un programa específico de gestión del dispositivo concreto que tenga instalado el PC, sino que es capaz de adaptarse a la especificación de PXE y utilizar el propio driver contenido en la pequeña ROM del propio interfaz de red. Esta característica da una flexibilidad enorme a la hora del arranque de red, ya que permite gestionar cualquier ordenador moderno que tenga una ROM compatible con el estándar PXE.
Además, todos los sistemas de gestión de arranque que hemos mencionado tienen la posibilidad de gestionar el inicio de otros sistemas operativos (como sería el de Microsoft Windows en cualquiera de sus versiones o como el GNU-Hurd o el Free-BSD) lo que nos permite instalar diversos sistemas en un solo PC y utilizar el más adecuado en cada momento. También son capaces de presentar las opciones de arranque en forma de menú, de tal forma que sea el propio usuario el que elija la opción de inicio más adecuada para su ordenador en cada momento, o en su defecto se elija una de forma automática al pasar un cierto tiempo. Esta última característica resulta muy interesante para la realización de tareas de gestión automáticas sin intervención del usuario.
También para GNU/Linux y para otros sistemas operativos hay otros sistemas disponibles de gestión de arranque que permiten realizar esta tarea en ordenadores más antiguos, previos a la especificación del sistema PXE. Son principalmente Netboot(7), Etherboot (8), NILO (53), Boots (3), Bootmagic (36) o Bp-batch (31) que no trataremos aquí en profundidad por salirse de nuestro espacio de acción, pero que el lector puede consultar a través de las referencias aportadas.
Una de las principales ventajas con respecto a la gestión del sistema GNU/Linux viene de la flexibilidad en el almacenamiento de sus datos. Así, por ejemplo, es posible generar la instalación un sistema GNU/Linux con todas sus aplicaciones perfectamente funcionales en un sistema de ficheros comprimido y de sólo lectura accesible desde un CD-ROM (véase el caso de Knoppix (43)). Baste mencionar que basándose en este ejemplo sería sencillo crear un sistema que en lugar de utilizar un CD-ROM con control de arranque, ofreciese lo mismo utilizando un sistema de disco de red de sólo lectura.
Otra de las tareas que es necesario realizar en el proceso de instalación o regeneración de la máquina es la de particionar el disco duro local. Hay algunas aplicaciones que permiten realizar esta labor, no sólo para los tipos de sistemas de ficheros de Linux, sino también para otros tipos de sistemas de archivos. Así, podemos hablar de fdisk (41), el más potente por sus opciones de configuración, o de Disk Druid que viene en la distribución de RedHat y permite realizar la configuración de las particiones del disco duro de forma automática, en función del espacio disponible.
Si hablamos ahora de las herramientas de instalación automática del sistema operativo Windows XP Professional, aunque hay ciertas facilidades de red que permiten realizar la configuración automática de los dispositivos soportados por el sistema operativo, no hay tantas facilidades disponibles para el administrador.
Así, el soporte para gestionar la instalación a través de la red es más bien escaso, dado que obliga a que el administrador disponga de los drivers de configuración de los dispositivos de red para el sistema operativo utilizado durante la instalación que es de tipo MS-DOS. Esta es una de las desventajas que tiene frente al sistema operativo GNU/Linux, ya que en Linux se puede realizar la instalación con el mismo núcleo que se utilizará posteriormente para el ordenador en su uso normal, usando por tanto el mismo código para la gestión de los diferentes dispositivos en tiempo de instalación y en tiempo de uso.
Además, después del proceso de instalación del sistema operativo, y aunque la instalación se haga de forma desatendida mediante la configuración del programa Sysprep (24), hay realizar el rearranque del sistema varias veces. Este programa, aparte de permitir la instalación de red sin requerir la presencia del administrador, se encarga de la introducción de los datos de licencia del producto y la generación automática del identificador único de sistema (SID), lo que es fundamental para la compartición de datos a través de la red.
La gestión es particularmente más complicada, si queremos que la gestión de las cuentas de usuario sea realizada también a través de la red (operación que en la jerga de Windows viene a llamarse ''unirse al dominio''), sobre todo si deseamos que el controlador principal del dominio no sea un ordenador de la plataforma Microsoft Windows (véase la información sobre el proyecto Samba (25)) ya que el protocolo utilizado para este tipo de servicios está lejos de ser una especificación abierta.
En este entorno (en el que un servidor Samba da servicio de dominio a un servidor XP) hemos detectado otros problemas añadidos, como viene a ser el caso de la clave privada generada para la conexión al dominio caduca cada mes, con lo que hay que regenerar la clave o el servidor cada vez que ha caducado(27).
Este tipo de sistema también da más trabajo al administrador porque la mayor parte de las aplicaciones no vienen integradas en el mismo soporte y formato que el sistema operativo siendo necesario realizar procesos que permitan automatizar la instalación y desinstalación de las mismas, como por ejemplo la herramienta Autoit(23). En este sentido también podemos utilizar una aplicación llamada WinstallLE (39) que permite realizar un análisis diferencial del estado de disco duro y registro de Windows y generar una imagen instalable de forma automática.
Tampoco está optimizado el uso de recursos en red en Windows, dado que la mayoría de las aplicaciones requieren estar instaladas en local (en el disco duro del ordenador que las pretende utilizar) en lugar de ser posible instalarlas en sistemas remotos que permitan el acceso concurrente, a través de la red, al código de las aplicaciones.
También hay que añadir al capítulo de problemas de este tipo de sistemas operativos, que la instalación de los mismos requiere que el núcleo del sistema operativo se almacene localmente y esté disponible de forma permanente a través de un dispositivo de almacenamiento no volátil (como por ejemplo un disco duro), no siendo posible la carga del mismo desde la red de forma nativa. Además, el núcleo del sistema operativo tiene una gran cantidad de requerimientos tales como que el sistema de almacenamiento ha de tener un formato determinado (NTFS) si queremos utilizar las características de gestión de permisos de acceso entre usuarios o como que el sistema de almacenamiento ha de ser de lectura y escritura.
No hay que olvidar mencionar que también hay otras herramientas de Microsoft que permiten automatizar la instalación del sistema operativo de forma desatendida, tal y como es el Setup Manager Wizard o que permiten la clonación de las instalaciones de servidores Windows, como viene a ser el IntelliMirror para Windows XP que dispone de una herramienta llamada RIS (acrónimo inglés de Remote Installation Services).
También hay otros proyectos que pretenden implementar sistemas de instalación desatendida de sistemas Windows desde servidor. Así, podemos mencionar Unattended (32) y Realmen (33). También hay gran número de páginas dedicadas a la recopilación de información y artículos que versan sobre el tema en Labmice.net (34) y en Willowhayes (35).
Uno de los sistemas de administración automática más divulgados para gestionar máquinas Windows es Rembo Auto-Deploy (28), un sistema a su vez basado en Windows NT/2000. También ofrece la posibilidad de gestionar máquinas GNU/Linux, pero, al igual que con Windows, siempre se basa en la regeneración local de una imagen de disco creada a partir de una instalación nueva en un sistema cliente idéntico, no permitiendo realizar instalaciones automáticas de sistemas Windows desde la red, lo que puede ser una exigencia demasiado fuerte cuando se trata de automatizar la instalación de un conjunto de servidores suficientemente diverso, ya que cada imagen ha de corresponder estrictamente con el hardware del PC. Aunque integra la última tecnología en protocolos de gestión de red (PXE, DHCP y Multicast) otro posible problema que podemos mencionar es que está pensado para concentrar en un sólo servidor la gestión de múltiples clientes pero no para permitir la gestión simultánea de las imágenes desde diversos sub-servidores de imágenes, lo que obliga a que todos los clientes tengan acceso directo al servidor de administración.
Para realizar imágenes de disco capaces de iniciar el ordenador hay muchas aplicaciones que permiten automatizar la creación de las mismas y gestionarlas a través de la red. Así, están Norton Ghost(37), PQDI (Power Quest Drive Image (36)) para Windows XP y Partimage (38) para Linux.
Antes de poder recuperar las imágenes o instalar el sistema es conveniente utilizar alguna aplicación de gestión de particiones de forma automática para el sistema que estemos arrancando. Además de las de Linux, podemos utilizar Partition Magic (36) para Windows y el aefdisk (40) para MS-DOS.
Son muchos y muy variados los problemas que se pretenden resolver con este proyecto: desde el usuario poco experto que necesita reinstalar su equipo de trabajo hasta la actualización del sistema, pasando por la configuración del hardware o la creación de servicios distribuidos de forma sencilla. A continuación se describen algunos de los problemas más relevantes.
Para resolver algunos de los problemas anteriormente descritos pueden adoptarse diversas soluciones, algunas de las cuales nosotros hemos decidido no contemplar por el elevado consumo de recursos y la poca sostenibilidad del servicio que conllevan. Los que se muestran a continuación son los requisitos mínimos de nuestro sistema de administración centralizada.
El entorno en que se ha creado este proyecto es muy específico y bastante común en círculos académicos, pero puede que desconocido para la persona ajena al mismo. En la universidad en la que se ha realizado este proyecto, no se da soporte informático al personal de la misma, sino que a través del departamento de Servicios Centrales se provee de ciertas herramientas a los usuarios. Estas herramientas son: la conectividad electrónica entre las distintas escuelas e Internet y la gestión de los recursos que la hacen posible; la compra de ordenadores y material para la realización de las tareas docentes y la compra de licencias de productos software de uso general, como pueden ser sistemas operativos o aplicaciones de prevención y limpieza de virus informáticos.
Son el personal de administración y el personal docente encargado de cada asignatura quienes deben administrar (gestionar, instalar, actualizar, etc) los equipos informáticos que se hayan destinado a la realización de las asignaturas prácticas del departamento concreto al que pertenezca el laboratorio. Esto puede no ser un gran problema en un laboratorio pequeño con un par de ordenadores, pero en el DIT hay más de 1500 alumnos anuales a los cuales se les han de ofrecer cientos de equipos informáticos para realizar sus prácticas.
Por eso, el primer problema a resolver para la generación de este sistema de administración centralizada fue determinar qué tipo de soporte queríamos dar a nuestros usuarios (entendiendo por soporte las tareas que el personal asignado estaría dispuesto a realizar con el fin de resolver cada problema concreto del ordenador utilizado por el alumnado). La decisión tomada consistió en un firme compromiso en proporcionar a los alumnos un ordenador recién instalado en un breve espacio de tiempo y siempre que fuese necesario. La resolución de las cuestiones y problemas se haría solamente si el sistema sigue fallando después de recién instalado. Con esto, se ha conseguido una alta estabilidad y una gran facilidad de restauración de los entornos de pruebas propios de un laboratorio universitario de redes, programación y servicios telemáticos.
Al analizar los equipos informáticos de los que disponía el laboratorio, nos dimos cuenta de que, si bien estaban agrupados en conjuntos de máquinas exactamente iguales, la mayor parte de ellos carecía de un dispositivo fundamental para la instalación de los sistemas operativos de hoy en día: el lector de CDs. La única solución que no pasaba por instalarle previamente un lector de CDs a cada uno, era la utilización del sistema de interconexión de todos ellos: la red. A través de ésta, podrían compartirse los recursos necesarios para que todos los ordenadores tuviesen los mismos sistemas operativos y aplicaciones instaladas.
El análisis de la problemática y los requisitos que se nos plantean, nos permite llegar a la especificación de los objetivos finales del proyecto, que son los que se indican a continuación.
De hecho, algunas de las tareas que más tiempo consumen se eliminan de forma completa. Así, podemos mencionar que se pretende que el administrador no realice ninguna reparación software de ninguno de los servidores que administra ya que la mayoría de las veces los problemas vienen derivados de la instalación de dos aplicaciones conflictivas o de la sustitución de controladores. Por ejemplo, si un computador de tipo cliente deja de funcionar total o parcialmente, en lugar de invertir una gran cantidad de tiempo en averiguar el problema y tratar de solucionarlo, se recurre a la reinstalación o a la regeneración de su sistema completo y, en caso de que no sea suficiente, se buscará el problema en profundidad.
Este sistema tiene una ventaja crucial que resulta de la división del trabajo: de esta forma, el que reinstala o regenera de forma automática y desatendida ya no tiene por qué ser quien crea los procesos de reinstalación o quien está especializado en la resolución de los problemas que pueden surgir después de aplicar los procesos de administración cero.
Además, en caso de que el grupo de trabajo no sea lo suficientemente grande como para estar muy especializado, la parte monótona y rutinaria de las tareas del administrador se ve ampliamente recortada, permitiéndole a éste invertir más tiempo en la mejora del sistema de gestión centralizada.
Tan es así, que sería posible que el propio usuario del ordenador realizase las tareas de regeneración o reinstalación por sí mismo y sin depender de nadie más. Esto requeriría un control de acceso al sistema de regeneración o reinstalación automática cuya implementación es posible con la tecnología de que disponemos.
Desde un punto de vista tecnológico, se pueden entrever muchas posibilidades diferentes a la hora de plantearse la solución técnica de las necesidades de este proyecto. En este apartado pretendemos realizar una breve discusión de las mismas apuntando sus ventajas e inconvenientes más importantes. Explicaremos primero los procesos de instalación plenamente funcional del sistema operativo, que siempre son previos a la regeneración del mismo. Tanto los procesos de regeneración como los de instalación pueden ser de tipo manual o de tipo automático, dependiendo de si es necesario que una persona interactúe directamente o no con el procedimiento respondiendo a las preguntas de configuración que sea necesario. Hemos llamado procedimientos desatendidos a aquellos que permiten la gestión de un ordenador sin ninguna intervención del usuario. La distinción entre desatendido y automático viene a ser que mientras que para un procedimiento desatendido no hace falta nadie delante del ordenador, para un proceso automático necesitamos al menos alguien que decida qué tarea es la que se tiene que realizar y que esté delante del ordenador para llevarla a cabo.
Los sistemas de instalación automática son muy dependientes del sistema operativo que se desea instalar. Aunque en el pasado no era común encontrar sistemas operativos capaces de gestionar su propia instalación sin la necesidad de tener un administrador que respondiese a las preguntas, esta tendencia se invirtió hace pocos años al crecer la necesidad de administrar de forma más barata los ordenadores de grandes corporaciones y grupos de usuarios.
Aunque esto es así, por desgracia, este tipo de procedimientos no se han desarrollado para todos los sistemas operativos que podemos encontrar en el mercado y será necesario crearlos en los casos menos afortunados. Este tipo de trabajo (creación de sistemas de instalación automática) suele requerir un gran esfuerzo, están muy vinculados con el sistema operativo objeto de la instalación y, a parte de ser poco exportables, difícilmente serán capaces de adaptarse a los posibles cambios en los procedimientos de instalación del sistema operativo en cuestión. Por todo esto, en la mayoría de los casos parece más recomendable acudir a procedimientos de regeneración en lugar de reinstalación, de tal forma que aunque se tenga que realizar manualmente una de las instalaciones el resto puedan partir de la imagen generada.
Este tipo de sistemas utilizan las configuraciones almacenadas en algún lugar conocido para inicializar los sistemas de instalación y proporcionarles las respuestas a las preguntas que el usuario o administrador habría de contestar de forma manual.
Hay diferentes lugares posibles para guardar estas configuraciones de instalación. Los más comunes son los que se muestran a continuación (en la sección 3.4.2 se dan amplios detalles de la fase de arranque del ordenador PC):
De esta forma, en caso de utilizar en nuestro grupo de ordenadores un sólo tipo de sistema operativo, podríamos reinstalar todos y cada uno de ellos en un breve espacio de tiempo, lo que nos permitiría gestionar granjas de ordenadores con una gran facilidad.
Uno de los grandes inconvenientes de los sistemas de instalación automática es la heterogeneidad del hardware que utilizan los ordenadores que pretendemos instalar. También está el problema de la instalación automática de las aplicaciones, ya que éstas pueden venir separadas del sistema operativo. Por último hay que contar con la problemática de la recuperación de los datos del ordenador previos a la instalación automática, que suele ser necesario mantener.
Tipos de regeneración:
Para que la regeneración o la instalación de un sistema operativo pueda no requerir la atención del usuario que pretende realizar la tarea, es necesario que el sistema sea capaz de autoconfigurarse. Ésto se hace normalmente gracias a la información contenida en algún soporte alternativo que permite obtener la información que el propio usuario proporcionaría de forma manual. En esta sección se describirán algunos de los métodos más extendidos a la hora de implementar este tipo de soluciones. Algunas implementaciones posibles son las que se mencionan a continuación en sus diferentes estados y fases. En este apartado nos referiremos a las tareas de regeneración exclusivamente, pero el lector habrá de tener en cuenta que estos procedimientos también se pueden aplicar a la instalación indistintamente, así pues, lo que digamos del uno en este apartado será válido de forma general para el otro.
Como en todo sistema de tipo secuencial y automatizable, es muy conveniente partir de un estado estable y conocido a partir del cual realizar la implementación del sistema que gestione el resto de las fases. Nosotros consideramos que el estado inicial ideal para este sistema de recuperación desatendida es el de que el ordenador que se pretende regenerar esté apagado.
Esta consideración no es trivial, aunque pudiera parecerlo. Todo sistema de regeneración que se precie de serlo, debe regenerar la parte permanente de datos del ordenador sin necesitar ningún requisito previo para realizar las tareas de regeneración automática, salvo, claro está, los mínimos imprescindibles (acceso a los recursos físicos necesarios).
Hay sistemas de recuperación automática que están basados en tener un sistema operativo y una aplicación instalados que permitan gestionar el proceso de recuperación de datos, aunque éste sea de tipo automático y/o desatendido, pero éstos vendrían a ser más parecidos a sistemas de backup que sistemas de regeneración.
Partamos, por tanto, de que el ordenador de tipo PC a regenerar está debidamente configurado para que la BIOS detecte las unidades de arranque configuradas para iniciar el sistema operativo desde ellas. Será necesario que el usuario del sistema de regeneración inicie la computadora desde cero. Para ello, sería necesario apagarla -si está encendida- y volver a encenderla.
Para que la regeneración sea totalmente desatendida, realmente no debería ser necesario que nadie tuviese que pulsar el botón de encendido del PC. Por ello, se han desarrollado sistemas de arranque remoto que permiten iniciar un ordenador sin más que tener acceso a alguno de sus recursos de la forma adecuada y que ésta opción esté previamente soportada y configurada en el sistema (BIOS).
Por supuesto, para que el ordenador pueda iniciarse a la llegada de una determinada señal externa, ha de permanecer encendido al menos un pequeño subsistema de gestión de arranque que permitirá el arranque del ordenador completo. Eso supone que cuando el usuario apague el computador realmente sólo apagará la parte principal del mismo, quedando este subsistema encendido y alerta a la espera de la señal o señales que está preparado para detectar.
Los subsistemas de arranque remoto tienen diferentes nombres dependiendo del tipo de señal que el ordenador espere recibir para iniciarse. Así, podemos mencionar, entre otros:
La siguiente tarea que es necesario realizar en un sistema de tipo PC es gestionar el arranque o inicialización del mismo. Este proceso, es el que lleva al ordenador a cargar un sistema operativo en memoria, y por lo tanto el que inicializa los recursos disponibles del sistema (CPU, memoria, adaptadores, etc). Para hacerlo hay diferentes opciones a disposición del administrador. Las analizaremos para ver qué opciones nos ofrecen.
En este caso, el ordenador PC al inicializarse tiene disponible, a través de alguna de las unidades de datos extraíbles (como vienen a ser la disquetera o el lector de CDs o DVDs), un disco que contiene un pequeño sistema operativo y (normalmente) el programa que se utilizaría para regenerar el disco duro del ordenador. El ordenador, al arrancar, dará control a este pequeño sistema operativo.
En algunas ocasiones, el disco extraíble utilizado para la recuperación podría incluso contener la información que deseamos volcar sobre el disco duro del ordenador lo que resultaría muy cómodo y eficiente.
Son sistemas que utilizan un dispositivo hardware extra, normalmente diseñado expresamente para este tipo de sistemas, cuya misión es la de gestionar el arranque del ordenador desde una imagen almacenada en el mismo y que está configurada para permitir la copia de los datos que se desean recuperar bien desde un servidor de red que se la proporcione o bien desde algún otro dispositivo extraíble o no del ordenador.
Este tipo de sistemas suelen ser de tipo propietario y más recomendables en entornos de aplicación específica. Su hardware constituye un gasto extra ineludible y no suele tener capacidad de expansión. La memoria que utilizan es de tipo no volátil, lo que permite el acceso aleatorio a las posiciones de la misma. Para el ordenador que la alberga aparece como un disco duro o como un programa en memoria que recibe control de la BIOS y en fase de arranque suele ser de sólo lectura, de tal forma que un fallo en el proceso o la interrupción del fluido eléctrico no deterioren la información que contiene.
Todos utilizan una pequeña memoria no volátil de almacenamiento tipo EPROM o FLASH que contiene un programa de arranque de red que, mediante la utilización de unos protocolos de red expresamente diseñados para la configuración de sistemas y la descarga de datos, permite:
En los sistemas de los que disponemos, la información, que está inicialmente al alcance del programa de arranque que utiliza los servicios de red, sólo le permite establecer conexiones de red a un nivel muy bajo en la pila de protocolos. Este nivel es el llamado nivel de enlace en el modelo de comunicación OSI y sólo le permite comunicarse con otros equipos que estén en su misma subred local.
Por lo tanto, esta petición se hace únicamente a nivel del protocolo de enlace, lo que obliga a que:
También es interesante comentar que los datos traídos del servidor pueden utilizarse para presentar un menú al usuario y permitirle elegir entre varias opciones de arranque, algunas de las cuales llevarían a la instalación o regeneración del sistema, mientras que otras llevarían al arranque normal del sistema a partir de su propio disco duro o cualquier otro dispositivo. Este tipo de menús suelen tener configurada una opción de arranque por defecto que arranca el sistema de forma automática en caso de que se cumpla un tiempo de espera determinado.
En estos casos, el arranque se realiza en dos pasos intermedios: en uno se traen los datos de un menú y en el siguiente se carga o descarga la imagen seleccionada, a partir de la que se iniciará el sistema.
Resulta fundamental que el sistema operativo iniciado sea capaz de comprobar el estado y configuración de los diferentes dispositivos de que dispone. Con ello, se conseguirá que el sistema de regeneración disponga de un listado de características que permitan obtener los parámetros necesarios para realizar la autoconfiguración de la aplicación de regeneración desatendida. Así, por ejemplo, se podría elegir la imagen de regeneración en función de la dirección IP de la máquina a regenerar. Esta fase es sencilla de implementar y permite también evitar errores básicos en los procesos de regeneración posteriores.
Normalmente se basa en la ejecución de forma automática de un programa específicamente dedicado a la regeneración o instalación del sistema. Este programa utiliza los parámetros obtenidos en la fase anterior y puede ser diferente en función del sistema operativo que se vaya a regenerar o instalar. También puede ser diferente en función del tipo de medio a partir del cual se vaya a realizar. Más detalles sobre estos procedimientos se pueden encontrar en la sección 3.2 y en la sección 3.3.
Aunque no siempre tiene que ser así, normalmente la regeneración de un sistema le permite volver a funcionar de forma autónoma dentro de su red. En esta fase se da control al sistema recién regenerado para que actualice la información interna del sistema operativo y pase a ser un sistema totalmente independiente. El proceso comienza con un apagado del ordenador y un reinicio del mismo, esta vez sin utilizar los procedimientos de regeneración. Para ello, habrá que configurar el sistema central de administración y cambiar el estatus de la máquina de forma que no entre en un bucle de regeneración en el caso de que realice una nueva petición de arranque de red. Igualmente, habrá que quitar el disco de arranque si es que la regeneración no se hizo a través de la red.
En esta fase, se configuran los servicios y se realizan las actualizaciones del sistema operativo. Una vez hecho esto, se comprueba el funcionamiento del sistema y se da por terminado el proceso de regeneración.
El estado final es dependiente del tipo de ordenador que hemos regenerado. En nuestro caso hemos contemplado dos tipos de ordenadores: servidores y clientes. Si el ordenador regenerado es del primer grupo, parece conveniente que permanezca encendido después del proceso, para así continuar dando servicio a través de la red de aquello para lo que esté configurado. En caso de pertenecer al segundo grupo, es decir, si el ordenador es un sistema cliente, probablemente resulte más conveniente apagarlo hasta que algún usuario decida utilizarlo.
Dada la gran cantidad de datos que se necesitan para realizar la instalación del sistema operativo y sus aplicaciones, esta red local ha de tener un ancho de banda suficientemente alto. Además, resulta ser muy recomendable que todos los ordenadores tengan la misma tecnología de acceso a la red, ya que si unos acceden de forma más rápida que otros a la red, los más lentos se podrían ver desfavorecidos. Este es el caso de las redes Ethernet (802.3) en las que puede haber equipos conectados a 10, 100 o 1000 Mbps conviviendo en la misma red local.
La decisión tomada por el equipo de trabajo para la implantación de la red que daría servicio al nuevo laboratorio integrado en el sistema de administración centralizada fue la de utilizar la mejor tecnología disponible del momento, dentro del segmento de redes de área local, la norma Fast-Ethernet o también llamada 100baseTX. La red que se desarrolló se basó en una red de cableado estructurado de categoría 6 (capaz de permitir la interconexión de equipos a 1Gbps) dado que se preveía el posible futuro cambio de tecnología a 1000baseTX. Se han evitado en la medida de lo posible los equipos repetidores (Hubs) con el fin de dar el mejor acceso al equipo final y tener un mejor nivel de seguridad. Por eso, los equipos de interconexión utilizados para la mayoría de los equipos de usuario son conmutadores ethernet que están interconectados entre sí a través de un backbone de 1Gbps también basado en tecnología Ethernet.
Todos los servidores están conectados entre sí como mínimo a 100Mbps en un sólo conmutador de alta capacidad, para mejorar la velocidad de interconexión entre ellos. Incluso, dependiendo de la carga de red que soporten cada uno de ellos, es posible mejorar su servicio conectándolos al backbone a 1Gbps. Esto puede resultar necesario para servidores compartidos por todos los clientes (como por ejemplo los servidores de disco en red) o para servidores que requieran un gran ancho de banda (por ejemplo para poder hacer backups de forma rápida o para aplicaciones multimedia).
Para poder aislar grupos de ordenadores del laboratorio con el fin de hacer ciertas prácticas de administración de equipos sin interferir con el resto, también se ha dotado al laboratorio de sistemas de conmutación de ethernet capaces de gestionar redes virtuales o VLAN (48) (véase la especificación 802.1Q para más información). Esta tecnología también se puede utilizar para hacer prácticas de gestión de routers en equipos que tienen un sólo interfaz de red, para eso los routers han de ser capaces de acceder a varias VLAN a través de él.
Para poder hacer una monitorización a nivel de trama ethernet de algún equipo concreto en caso de problemas, también debe ser posible configurar el conmutador ethernet para que repita en uno de sus puertos todo lo que reciba del puerto conflictivo.
La red que hemos implementado para interconectar los equipos es una red estándar IPv4, aunque en el futuro se prevé la necesidad de crear redes de tipo IPv6 y proveerlas de los mismos servicios de que disponen las actuales. La red principalmente hace uso de servicios unicast aunque, para poder realizar determinadas prácticas de protocolos, también están configuradas rutas multicast locales.
La red de un laboratorio debe ser siempre considerada una red de pruebas y, como tal, también puede ser una red insegura (resulta fácil imaginar que algún alumno apurado de tiempo pretenda copiar prácticas o conseguir claves de acceso a través de la red).
La red de los laboratorios está dividida en dos subredes IP diferentes separadas por un router. La red más externa (y más próxima a Internet) es la que alberga los servidores públicos del laboratorio (DNS, HTTP, HTTPS, SMTP, etc). La red más interna, por otra parte, es la que utilizan los ordenadores del laboratorio propiamente dicho.
A su vez, la red más externa está conectada a Internet a través de un cortafuegos. El router hace forwarding a nivel IP entre las dos redes y también permite (a través de un proxy) que las máquinas de la subred interna del laboratorio tengan acceso a los servidores HTTP, HTTPS, FTP y GOPHER de Internet, del laboratorio y del DIT.
Todos los servidores mencionados están basados en sistemas GNU/Linux RedHat 7.3. El proxy está configurado mediante Squid (44), mientras que la administración del cortafuegos se realiza con el sistema Iptables (45) y Fwbuilder (46).
Para la realización de este proyecto no sólo es necesario crear buenos procedimientos de automatización de las configuraciones e integrarlos entre sí para permitir el máximo rendimiento (como iremos contando en este capítulo), sino que también juegan un papel importante las características de las máquinas que se pretenden administrar. De este modo, será fundamental (para evitar tener que hacer trabajos extra) que los ordenadores cliente del sistema de administración centralizada sean máquinas compatibles con el estándar PXE (11). Hoy en día la práctica totalidad de los ordenadores con la tarjeta de red integrada (sobre todo en equipos de la marca Intel, que fue uno de los principales impulsores de la especificación) tienen la ROM de la tarjeta de red preconfigurada y accesible para gestionar el arranque mediante PXE. Si no se dispone de equipos de estas características, habrá que instalarles el hardware y el software necesarios para que dispongan de ellas (como pueden ser las propias ROM o los programas de las mismas).
Además, para la gestión de equipos que están en sitios públicos y expuestos al robo eventual, también será necesario que los ordenadores tengan algún tipo de elemento antirrobo que permita introducir un candado o una cadena de seguridad para anclarlos físicamente al laboratorio.
Otro consejo fundamental para la administración de este tipo de redes, es asegurarse en la compra una garantía del fabricante suficientemente amplia para que el personal técnico no tenga que realizar reparaciones de hardware en estos equipos al menos en los primeros 3 años de funcionamiento. Hoy en día, este tipo de garantías suelen ser in-situ y cubrir el 100% de los dispositivos del ordenador, lo que evita pérdidas de tiempo del personal técnico en la detección de problemas en la mayor parte del tiempo de vida útil del ordenador cliente.
En cuanto a estas reparaciones locales, aunque no serán necesarias si se negocian buenas garantías, siempre hay que tener algunos repuestos disponibles para los equipos más críticos. Así, por ejemplo, resulta conveniente tener algunas fuentes de alimentación, ventiladores y disipadores, lectores de CD, discos duros y disqueteras, además de personal experto en hardware de PC.
También por estar en lugar público, resulta necesario inhabilitar el acceso del usuario a la BIOS del sistema mediante la configuración de una clave de acceso para la administración. Sólo usando esta clave, se podrán configurar los parámetros de arranque del ordenador, y evitar que éste arranque desde otro medio que no sea la red (disquete, lector de CD-ROM o disco duro). Así, disminuirán los intentos de ataque al sistema o captura de claves mediante la instalación sin consentimiento de algún sistema operativo capaz de realizar estas tareas.
Por todo esto, será necesario tener personal preparado para ser capaz de configurar adecuadamente las BIOS de los ordenadores, administrar las claves de acceso y actualizar el firmware de las ROM de las tarjetas cuando sea necesario, ya que puede haber diferencias importantes en el tiempo y la funcionalidad de arranque entre dos versiones diferentes del mismo.
El sistema de arranque de red debe estar accesible en el momento justo posterior a la fase de la BIOS y se debe configurar manualmente la primera vez que se pone en funcionamiento el ordenador.
Una vez que el computador ha pasado la fase de inicialización hardware de la BIOS, éste comienza la fase de arranque. Si la hemos configurado adecuadamente, se accederá al programa almacenado en la ROM de la tarjeta de red para realizar a través de ésta una petición de tipo PXE. Para que esto funcione así, la tarjeta de red ha de estar conectada a un equipo repetidor de red (hub o switch en caso de ethernet) y tener el LED de enlace activado, indicando que pueden enviar y recibir tramas por ese interfaz.
El programa de la ROM de la tarjeta de red realizará primeramente una petición de tipo PXE (que debería ser respondida por un servidor de PXE). Si esta petición no es respondida después de un cierto tiempo, se efectúa de nuevo hasta un máximo de 3 veces. Si sigue sin ser respondida, a continuación, se realiza una petición DHCP (que puede responder tanto un servidor de DHCP como uno de BOOTP ya que los protocolos si bien son distintos, son compatibles entre sí). Sólo si esta petición (repetida también hasta 3 veces) no es respondida adecuadamente, se continúa el arranque a través del siguiente dispositivo de arranque configurado, ya sea éste el disquete, lector de CD-ROM o el disco duro. En caso de no haber ningún otro dispositivo configurado para continuar el arranque, se reiniciaría el proceso de arranque desde la ROM auxiliar del sistema. Si el proceso de arranque de red falla un número determinado de veces, el ordenador finalmente cesa en el intento y queda a la espera de un reinicio físico o un comando manual.
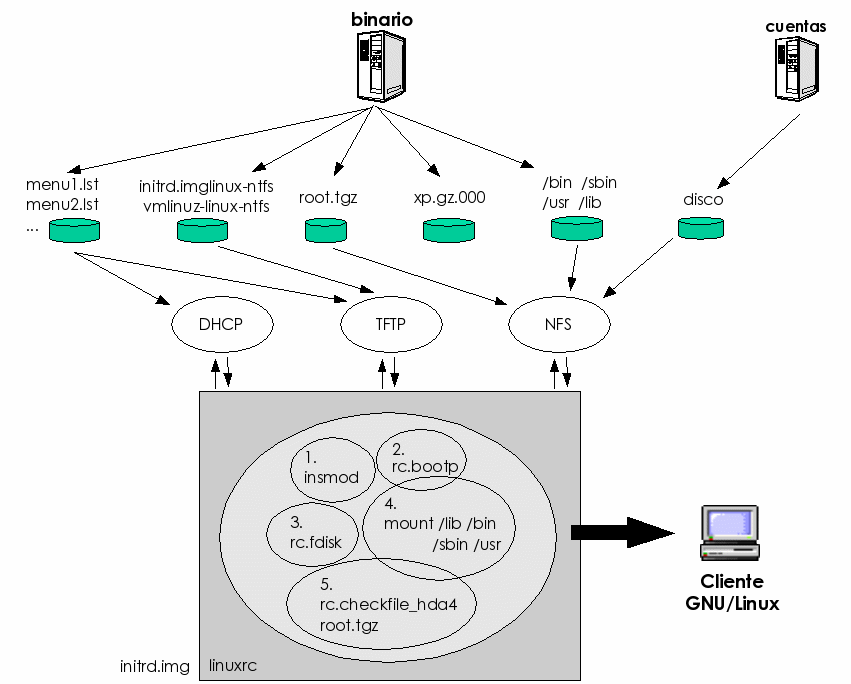
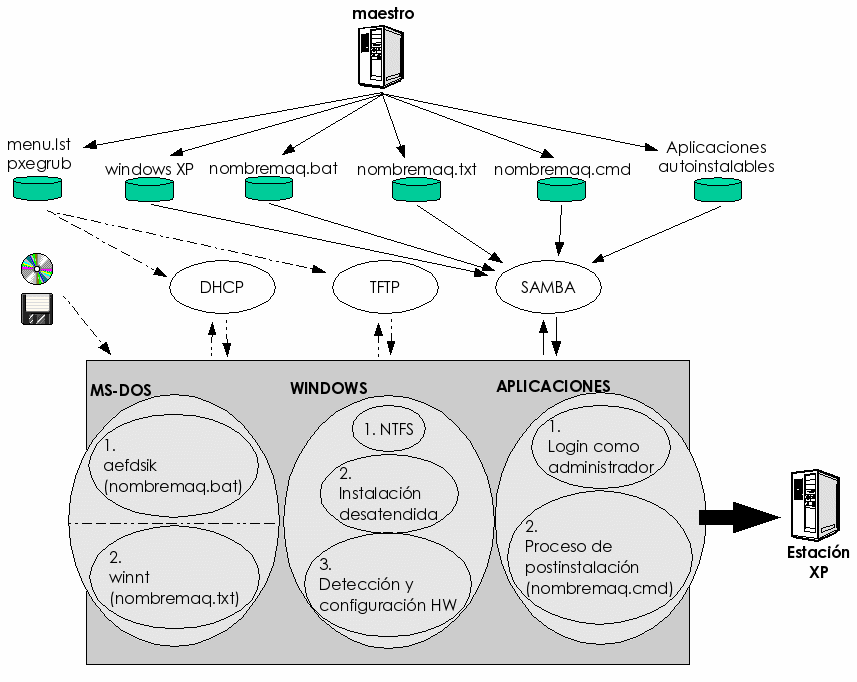
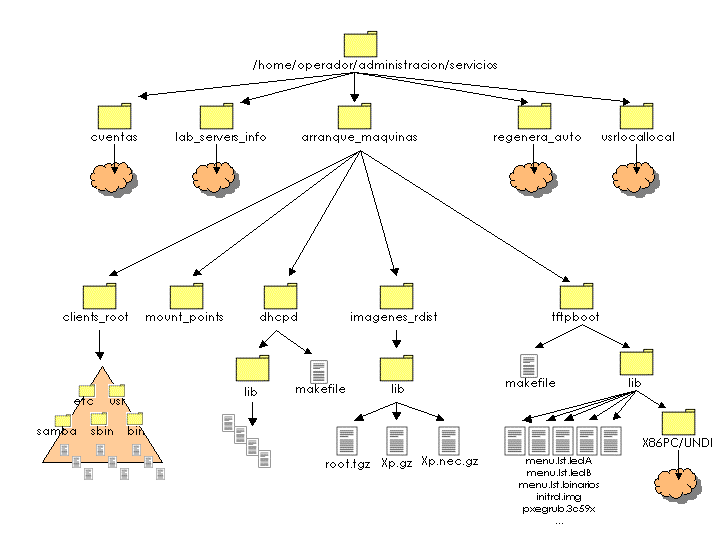
Actualmente, en los laboratorios docentes del DIT se utilizan 6 servidores de arranque. Están configurados para servir DHCP (12) mediante el software de ISC (47) y dan servicio de forma concurrente, compitiendo entre sí por responder al cliente sus peticiones de arranque de red. Una vez que el cliente obtiene una respuesta, utiliza el servidor que le ha respondido (o en casos específicos el que está configurado) para descargar mediante protocolo TFTP (21) un fichero que permita gestionar el inicio de la máquina local (normalmente mediante un menú de opciones que se ofrecen al usuario). Esta configuración del servicio, aunque obliga a que todos los servidores intenten responder a cada cliente que hace una petición DHCP, ha resultado ser muy conveniente, puesto que el cliente elige al servidor que más rápidamente le proporciona la respuesta, equilibrándose de forma automática la carga de los servidores y permitiendo manejar adecuadamente posibles problemas de congestión en servidores puntuales, ya que todos los servidores pueden dar servicio a cualquier cliente.
La configuración de cada uno de estos servidores DHCP es realizada por el sistema de administración centralizada y permite personalizar la configuración de cada servidor para que redirijan al cliente al fichero de arranque adecuado. Para ello, se parte de la base de un fichero de configuración común para todos ellos, que en lugar de apuntar a servidores concretos contiene ciertas palabras clave que son sustituidas por el nombre del servidor que se quiera configurar mediante una herramienta estándar de Unix (sed (49)), gestionándose todo el conjunto con la herramienta make (50).
Las imágenes y los menús que se descarga el cliente a través de TFTP también están en cada uno de los servidores y son exactamente iguales en todos ellos. La distribución y sincronización del árbol de directorios de los servidores TFTP se realiza mediante rdist (51). Aunque se podría haber utilizado para este caso rsync (52), rdist resulta más útil puesto que permite ejecutar en el servidor remoto (al que se ha distribuído el árbol) un scripta de configuración, que por ejemplo reiniciaría el servidor TFTP.
La imagen de inicio que el ordenador cliente descarga por TFTP, para nuestra configuración particular, puede ser la proviniente de dos sistemas software de arranque de los que hemos comentado algo previamente: GRUB (29) o Pxelinux (10). Si bien GRUB ha sido uno de los pioneros en gestionar el arranque a través de la red de ordenadores PC basándose en el estándar PXE, tenemos que decir que tiene un problema importante: sólo permite gestionar imágenes PXE para las tarjetas específicas que es capaz de soportar y cuyos driversb hereda de otro proyecto (Etherboot (8)). Por eso, cuando se usa GRUB y se quiere permitir el arranque de equipos PXE, es necesario utilizar de forma exclusiva las tarjetas soportadas. Por lo demás, GRUB es un gestor de arranque muy versátil y potente que permite la especificación del menú en un fichero también descargado por TFTP y especificado a través de una opción especial en el registro DHCP del cliente.
Las características de Pxelinux son bastante más potentes en este sentido, ya que permite gestionar (mediante la imagen descargada al ordenador cliente) la tarjeta de red, gracias a la utilización del driver de la misma que incluye el fabricante en la propia ROM, cumpliendo así, el estándar PXE. Para ello, el driver contenido en la ROM de la tarjeta de red ha de implementar una interfaz común, llamada UNDI (siglas de Universal Network Driver Interface). Con Pxelinux también es posible descargar un menú (aunque quizá menos potente y más difícil de configurar que el de GRUB) que permite mostrar al usuario las opciones de arranque de una forma clara y sencilla.
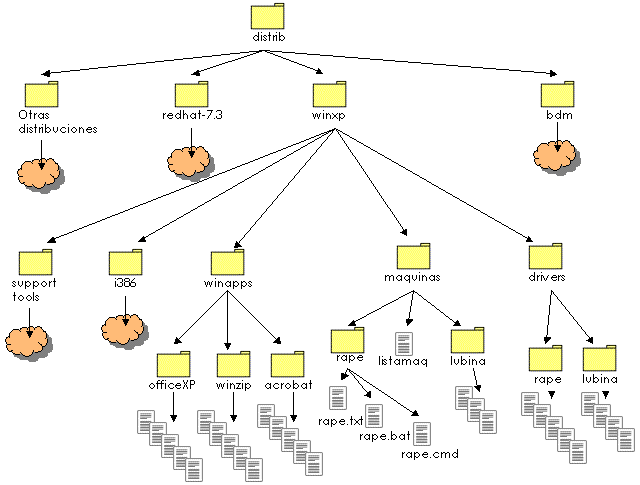
Dada la necesidad de múltiples sistemas operativos en los ordenadores cliente de los laboratorios docentes del DIT (Windows XP y GNU/Linux), hemos tenido que permitir en los ordenadores cliente el arranque desde el disco duro local. Ya explicamos con anterioridad que no es posible, hoy por hoy, descargar el núcleo de Windows XP desde la red y darle control, por lo que este sistema operativo ha de quedar instalado en el disco duro del ordenador.
Sin embargo, con el sistema operativo GNU/Linux sí es posible descargar el núcleo a través de la red y por lo tanto no resulta necesario tenerlo instalado en el disco local (más que las partes que consideremos necesarias para evitar el uso excesivo de la red). El problema de ubicación del Windows XP es una pega importante, ya que no permite gestionar íntegramente el ordenador desde la red, pero también tiene una pequeña ventaja y es que en caso de no funcionar los servidores de arranque de red (por cambio, fallo o actualización de los mismos) el sistema podría arrancar de disco local y seguir dando servicio al usuario de la máquina cliente.
Si vamos a la gestión física del disco duro del sistema, ésta se compone de 3 fases: particionado, formateo e instalación del sistema operativo. Estas tareas se pueden realizar de forma automática en GNU/Linux pero no resulta tan sencillo en Windows XP. Por eso hemos adoptado una solución mixta que resuelve el problema y que consiste en la utilización del sistema operativo GNU/Linux para realizar la mayor parte de las tareas de particionado y formato de disco. En concreto se usarán fdisk (41) para particionar los discos de forma automática, mke2fs para formatear las particiones de GNU/Linux (ext2 y ext3) y partimage (38) para regenerar tanto el formato como los datos de las particiones de Windows XP (NTFS).
Hay varios tipos de instalación que han sido integradas en el sistema de administración centralizada y para cada uno de ellos, dedicaremos una subsección en este apartado. La clase de instalación que se pretende gestionar es aquella que se puede realizar de forma automática y desatendida, sin requerir la presencia de un administrador para la realización de la tarea. Hay que recalcar que el sistema diseñado está configurado para realizar las instalaciones de ciertos sistemas operativos (Windows XP y GNU/Linux) y que cambiarlos puede suponer cambiar en parte los detalles, pero se mantendría en todo caso la filosofía general del procedimiento.
Para independizar las funciones y aumentar el rendimiento, se han creado tres niveles jerárquicos diferentes:
El servidor principal está diseñado de tal modo que es el servidor desde el que se instalan y se administran los servidores secundarios (exactamente igual que se instalan los clientes desde los servidores secundarios). Por eso, la distribución jerárquica de funcionalidades permite conseguir una ventaja añadida: desde el sistema maestro es posible regenerar todos los servidores y clientes en caso de catástrofe general, lo que aporta una gran robustez y fiabilidad.
Para realizar la tarea de instalar de forma desatendida un servidor GNU/Linux es muy conveniente basarse en la utilización de las herramientas de autoinstalación que el proveedor (de la distribución concreta que queramos instalar) suele proporcionar. De esta forma, se ahorra una buena cantidad de trabajo. Aún así, estas herramientas no son todo lo completas que resulta necesario ya que no se encargan de realizar más que una configuración muy básica de las aplicaciones instaladas en el servidor y además no son capaces de instalar aplicaciones que no pertenecen a la distribución.
Para obtener un servidor GNU/Linux completamente instalado y configurado será necesaria la utilización de otras herramientas (que en este caso se han desarrollado expresamente para este proyecto) que permitan automatizar la creación de los ficheros de configuración utilizados por los autoinstaladores y para configurar y añadir aplicaciones (ajenas o no a la propia distribución).
Los servidores RedHat GNU/Linux instalados, usan la versión 7.3 de la distribución RedHat Linux y, por tanto, las herramientas creadas están particularizadas para este sistema operativo, aunque se prevé la generalización de las mismas para otras distribuciones también de GNU/Linux.
El requisito inicial para la generación de un fichero de configuración de la herramienta Kickstart (el autoinstalador de sistemas de RedHat) es disponer de los detalles de configuración del hardware del servidor (relativos a los dispositivos físicos) y la lista de paquetes a instalar dentro de los disponibles en la propia distribución RedHat. Por detalles hardware se entiende la especificación del tipo de tarjeta de vídeo, tipo de disco y particiones, tarjeta de red, etc. La lista de paquetes predefine el software que se instalará en el servidor GNU/Linux mediante Kickstart.
Esta lista de paquetes puede contener identificadores de grupos de paquetes (que ya vienen predefinidos en la instalación) o bien paquetes individuales. Los grupos de paquetes predefinidos suelen ser de propósito general y por tanto, poco apropiados para nuestro entorno, lo que nos obliga a generar nuestros propios grupos de paquetes para la instalación de nuestros servidores. Esta tarea deberá realizarse una única vez y habrá de ser llevada a cabo por el administrador teniendo en cuenta las necesidades comunes de la red de servidores que pretende administrar. En el caso de RedHat, la gestión de grupos de paquetes se realiza a través del fichero comps que aparece bajo el directorio /RedHat/base dentro del primer CD de instalación. En nuestro caso, podemos modificar este archivo según nuestras necesidades puesto que reside en un dispositivo de lectura y escritura que exportaremos por NFS para dar el servicio de instalación.
Aunque el proceso de instalación habitual utiliza un disquete o CD para gestionar el arranque de la máquina y comenzar la instalación desatendida, la opción más deseable para nuestro sistema es la utilización de la propia tarjeta de red para descargar los archivos de arranque e instalación. Para ello, habrá que administrar los diferentes servidores a partir de los cuales se gestionará el proceso.
Los posibles medios de instalación por red para el caso de RedHat son: servidor Web (HTTP), servidor FTP y servidor NFS. También cabe la posibilidad de utilizar un proxy para acceder a estos servicios, lo que permite el acceso desde redes aisladas o parcialmente aisladas, siendo necesario modificar la configuración adecuadamente.
El arranque de las máquinas se hará según se describe en la sección 4.4, pasando como parámetro al núcleo de Linux (vmlinuz) el tipo de instalación y la localización en la red del fichero de configuración de la instalación desatendida (ks=nfs:AC_IP_DEL_SERVIDOR:/kickstart/ks.cfg, donde habría que sustituir AC_IP_DEL_SERVIDOR por la dirección IP física del servidor que contiene el archivo ks.cfg).
Mediante Kickstart también es posible configurar la ejecución de tareas en la fase inmediatamente anterior y posterior a la fase de instalación, lo que proporciona ciertas facilidades de configuración fuera de las estrictamente contempladas (como por ejemplo, el enviar un correo al administrador).
Dada la cantidad de factores modificadores, la tarea de generación del fichero de configuración de Kickstart para cada uno de los servidores ha de ser asumida por nuestro sistema de gestión centralizada. Para ello, se partirá de una base de datos que deberá estar disponible y que deberá contener las características particulares de cada servidor. Por eso, para complementar las tareas de instalación que automatiza el Kickstart, han de desarrollarse algunas herramientas que permitan realizar en el sistema recién instalado el resto de tareas de administración. También será necesario crear ciertas infraestructuras que puedan ser utilizadas para el resto de los servicios de administración.
Se enumeran a continuación las tareas más importantes a desarrollar por el sistema de administración centralizada, dentro de las que implican la instalación automática y desatendida de nuevos servidores GNU/Linux:
Hemos llamado clientes GNU/Linux a los ordenadores con sistema operativo GNU/Linux que se utilizan en el laboratorio para realizar las prácticas docentes, para evitar la ambigüedad con los servidores instalados de forma automática de la sección 4.6.1. Por motivos de rendimiento y aprovechando que todos los clientes GNU/Linux del laboratorio son prácticamente iguales entre sí, salvo en detalles de configuración del hardware, decidimos evitar los procesos de instalación automática como los descritos para servidores GNU/Linux y realizar una instalación a medida para ellos, que está a medio camino entre la gestión de imágenes y la instalación de servidores.
El proceso fundamental se basa en crear un fichero comprimido que agrupa los archivos existentes en un servidor GNU/Linux previamente instalado con los requisitos necesarios. Este archivo se genera en el servidor de administración de forma automática a partir de una lista de archivos requeridos. Después, este fichero se transmite por la red, se descomprime en el disco duro y se le cambian los parámetros necesarios para que el cliente pueda iniciar sus dispositivos particulares.
Los detalles de implementación de la solución adoptada para manejar la problemática de esta sección, se detallan en el punto 5.2.3.
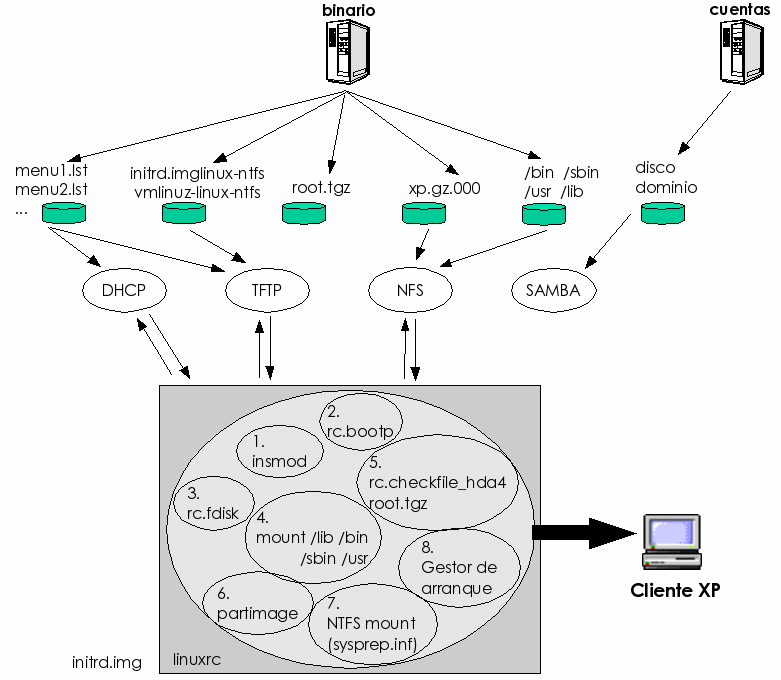
Mientras que para GNU/Linux todos los clientes eran iguales de forma casi total porque se puede instalar en todos ellos prácticamente el mismo núcleo del sistema operativo (diferenciando entre ellos la CPU), en el caso de Windows XP nos encontramos con que es necesaria una imagen diferente por cada uno de los ordenadores con placa base diferente.
Esto significa, que vamos a necesitar agrupar nuestros ordenadores en función de su placa base y crear una imagen de regeneración para cada uno de esos tipos. En nuestro laboratorio, debido a la política de compra de ordenadores, tenemos grupos lo bastante amplios como para gestionarlos todos con sólo dos imágenes diferentes. Si esto no fuese así, la tarea de administración de este tipo de regeneraciones podría llegar a ser demasiado costosa.
La gestión de regeneraciones es una técnica que, en nuestro caso, sólo hemos decidido utilizar para reinstalar particiones con el sistema operativo Windows XP y formato NTFS, pero es lo suficientemente general como para poder ser aplicada a cualquier otro sistema operativo y tipo de formato de disco duro dentro de los que soporta la aplicación principal utilizada ello, partimage (38).
El proceso concreto se basa en el utilizado para la gestión de instalaciones para clientes GNU/Linux, pero usando una aplicación que es capaz de realizar la regeneración cruda de particiones de disco, regenerando a la vez formato (en el caso de Windows XP, NTFS) y datos de las mismas (árbol de directorios, archivos y ficheros) bit a bit. Esta aplicación es ejecutable en Linux desde la imagen de disco virtual descargada inicialmente de la red y permite regenerar la partición deseada desde un fichero que puede ser local o estar accesible a través de la red.
Los detalles de implementación se facilitan en la sección 5.2.4.
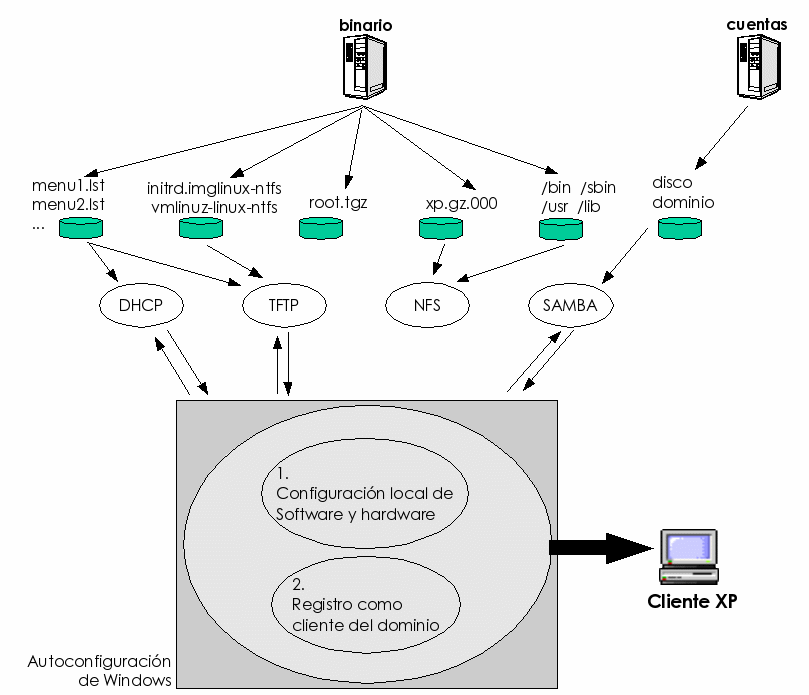
La instalación automática de clientes Windows XP es una técnica basada en las facilidades proporcionadas por el fabricante del sistema operativo (Microsoft (18)), para la instalación desatendida de las estaciones. Aunque hay varios documentos ((15,14)) que describen los esfuerzos realizados por esta compañía por facilitar la gestión de las tareas de instalación en entornos de grandes redes corporativas, la verdad es que no se han podido llevar a la práctica por diversos problemas de compatibilidad y rendimiento que hasta hace relativamente poco no se han llegado a resolver.
La solución adoptada por nuestro sistema de gestión se basa en la utilización de ciertas aplicaciones que permiten configurar los dispositivos locales (disco duro y tarjeta de red, principalmente) y obtener las configuraciones y los archivos de instalación a través de la red. Luego se efectúa una instalación desatendida también a través de la red y en una fase de postinstalación se generan los usuarios y se instalan las aplicaciones extra (no incluidas con el sistema operativo).
Los detalles sobre la implementación de este proceso para el sistema de administración centralizada se pueden consultar en la sección 5.2.5 y también a través de la documentación proporcionada por Pedro J. Pérez (62) y por Karl Bernard (61). Sobre la generación de instalaciones de aplicaciones automatizables para Windows hay más información en las páginas de Autoit (23) y WinstallLE (39) de Veritas, así como en Microsoft (18).
En esta sección, se pretenden agrupar aquellos servicios que son de carácter general y suelen ser, si no estrictamente necesarios, muy comunes no sólo en el entorno de aplicación de este proyecto sino en cualquier entorno moderno de trabajo cooperativo en Internet. Aunque la práctica totalidad de los servicios que se mencionan están basados en servidores implementados en el sistema operativo GNU/Linux, hay que tener presente que los ordenadores que los utilicen pueden utilizar cualquier otro sistema operativo, dado que los servicios que proporcionan son de uso común y su objetivo final es la interoperabilidad de sus clientes. Los servidores que ofrecen los servicios que se mencionan a continuación también están integrados en el sistema de administración centralizada, realizando el papel de servidores secundarios y por tanto estando directamente administrados desde el servidor principal de administración.
Es importante resaltar que en el modelo de sistema que hemos diseñado, los usuarios sólo tienen cuenta en los clientes del laboratorio, de tal forma que no se ejecutan sus tareas en ninguno de los servidores que gestionan su arranque o configuración. La gestión de usuarios se realiza siempre en el servidor principal de administración, que es quien se encarga de distribuir las configuraciones adecuadas a cada servidor.
En el sistema de gestión de usuarios hay varios aspectos importantes implicados. A saber:
La distribución de las configuraciones y la ejecución de alguna de estas aplicaciones, se realiza de forma periódica a través de un sistema llamado cron en los sistemas GNU/Linux, que no es más que un gestor de tareas a partir de patrones temporales (scheduler).
La gestión de impresoras es una de las tareas más complicadas de realizar desde servidores GNU/Linux. Si bien, la exportación a través de red de impresoras y la gestión de usuarios que las comparten es relativamente sencillo utilizando el sistema Samba, hay un problema fundamental que dificulta la gestión de las mismas: hoy por hoy, los fabricantes no realizan drivers para gestionar los trabajos enviados a sus impresoras para el sistema operativo GNU/Linux.
Este problema tiene dos consecuencias fundamentales: 1) no es posible generar los trabajos de impresión en el formato genuino de las impresoras, y 2) no hay drivers de control de impresora que permitan realizar la contabilidad de los gastos de cada trabajo impreso (papel, tóner/tinta, número de hojas, etc). Aunque hay varios proyectos que pretenden realizar estas tareas, normalmente el resultado es peor de lo que cabría esperar, siendo ésto especialmente cierto para las impresoras que soportan formatos obsoletos (tales como el formato PostScript de nivel 2 en lugar del más potente y moderno, de nivel 3).
Tampoco desde GNU/Linux se gestionan bien las fuentes de impresora o las fuentes True Type del documento, lo que muchas veces da problemas de calidad en los trabajos. Además, al no haber un sistema unificado de impresión en Linux, es cada aplicación la que se encarga de generar su propio fichero PS, que después habrá que traducir al nativo de la impresora, lo que aún crea más problemas.
Otro de los problemas de gestión, es el del control de las cuotas de impresión de los usuarios, difícilmente solucionable vistos los problemas anteriores y que se viene a añadir a los problemas típicos de este tipo de dispositivos: atascos, rellenado de papel y bloqueos de la impresora.
Dadas todas estas circunstancias, hay varias formas de acometer la problemática:
En nuestro diseño, en lo relativo al DNS se ha contemplado la existencia de un servidor secundario de dominio para gestionar las direcciones internas del laboratorio y permitir el acceso al servicio de resolución de nombres sin necesitar acceder al exterior del mismo.
Tener un servidor de nombres dentro de la red del laboratorio es muy conveniente para agilizar otros servicios, como el de proxy o el de correo electrónico. Este servidor de nombres, se gestiona mediante la aplicación bind de ISC (47) que es uno de los más estables y potentes entre los disponibles. Este servidor utiliza la misma máquina que hace de router y proxy del laboratorio, dada su posición estratégica en la red.
Para minimizar el uso de este servicio a lo estrictamente necesario, también se distribuyen a los clientes GNU/Linux ficheros con el direccionamiento interno del laboratorio (/etc/hosts).
El sistema de correo electrónico se ha dividido en dos partes. En una máquina, situada en la red pública de acceso, se recibe y transmite el correo de o hacia el exterior y se gestiona el correo de los profesores del laboratorio. En la otra, situada en la red privada del laboratorio, se gestiona el correo de los alumnos y se les da servicio a través de protocolo IMAP, IMAPS, POP3 y POP3S. Las listas de correo del laboratorio también están en este servidor.
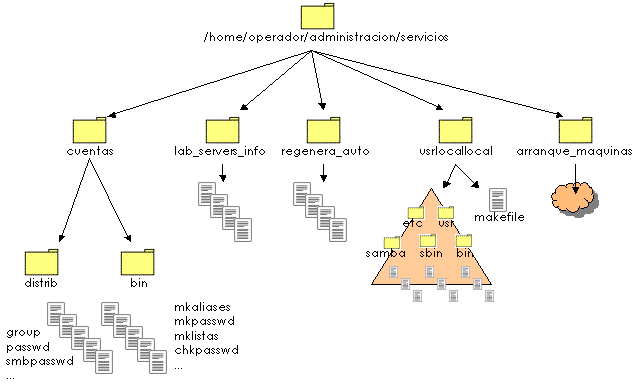
La gestión del correo implica crear las listas de correo que agrupan usuarios del mismo laboratorio de forma automática, así como crear las tablas de aliases de los servidores SMTP. Estas tareas son realizadas por un conjunto de scripts de distribución y gestión situados en el directorio cuentas del usuario operador en el servidor central de administración.
Para facilitar la gestión del correo por parte del usuario, se le proporcionan dos servicios extra, como son la posibilidad de reenviar todo el correo que reciba a algún servidor del exterior (técnica llamada forwarding de correo) y filtrar el correo en función del asunto, contenido, tamaño o remitente, entre otros.
El web es el procedimiento principal a través del que se difunde la documentación de las prácticas a realizar en el laboratorio. Ha de tener la máxima disponibilidad para posibilitar que los alumnos tengan acceso a ella al mismo tiempo que realizan las pruebas de laboratorio, sirviéndoles así de guía y de ayuda.
También se utiliza el servidor web para permitir al usuario cambiar su contraseña de acceso. Este servidor web, específicamente configurado para ser sólo accesible desde el interior del laboratorio, ejecuta un CGI (siglas de Common Gateway Interface, formato de archivo para la ejecución de programas en los servidores web) que permite cambiar tanto la clave de acceso para los clientes GNU/Linux, como la clave de acceso a los clientes Windows XP a través de Samba. Los scripts implicados en esta tarea llevan por nombre passwd.html y comprueba.cgi y están preparados para facilitarles la nueva información a los scripts que se ocupan de las tareas de gestión de usuarios.
Hay una máquina en el laboratorio expresamente configurada para dar servicio de disco remoto a los clientes tanto de sistemas Windows como de Linux. Para los primeros tiene configurado un servidor Samba, del que hemos hablado anteriormente. Para los segundos se utiliza NFS. Ambos servidores son capaces de gestionar los permisos del usuario, impidiendo que unos usuarios tengan acceso a la información de otros sin autorización, lo que garantiza el aislamiento seguro de las prácticas entre los alumnos.
Además, este servidor gestiona una cuota de disco para cada alumno, realizando un control de las mismas de forma periódica y enviando un correo electrónico al usuario en caso de que esté llegando al límite de uso. El programa que realiza esta tarea, también ha sido diseñado expresamente y recibe el nombre de ckquota.
También hemos decidido incluir en el sistema de cuotas el directorio en el que se almacena el correo del usuario (/var/spool/mail) para así gestionar de forma conjunta el disco total utilizado por cada alumno. Esto es particularmente crítico hoy en día, dada la tendencia expansiva del correo electrónico no solicitado o abusivo (spam).
Para ciertas prácticas de red, ha resultado necesario utilizar núcleos de GNU/Linux específicamente compilados para gestionar interfaces especiales de red. Dichos núcleos ofrecen las mismas posibilidades de acceso al resto de los dispositivos pero, por ser menos estables que los modernos, no se utilizan más que para las prácticas en las que el alumno lo requiere. También hay componentes hardware que, por no estar soportados en Linux por el fabricante, hay que instalar sus drivers en las máquinas Windows XP. Para permitir que el alumno gestione el hardware y pueda realizar las prácticas docentes, hay que dotarle de mecanismos de autenticación que le permitan hacer los cambios con privilegios de administrador. En GNU/Linux utilizamos sudo (54), mientras que en Windows tienen que utilizar una cuenta de administrador local para poder configurar el hardware.
En un entorno compartido en el que conviven muchas asignaturas prácticas resulta extremadamente conveniente proporcionar al usuario un sistema de reserva de puestos que le permita garantizar el acceso a un ordenador del laboratorio en una fecha y hora concretas y durante un turno completo. Esto es particularmente importante en las ocasiones en que sólo se puede realizar la práctica desde un ordenador concreto, siendo el caso de ciertas prácticas del laboratorio de Redes y Servicios Telemáticos, en las que se ha de configurar el equipamiento remoto que está únicamente conectado a éste a través de una red privada.
Este servicio ha sido desarrollado a partir de un proyecto (6) realizado en el marco de estos laboratorios en Diciembre de 2000. Las mejoras introducidas han permitido gestionar las reservas de forma sencilla a través del web. Mediante un sistema de autenticación local y un mapa de los recursos del laboratorio se permite al propio alumno elegir el próximo turno en el que realizará las prácticas, así como los equipos que utilizará para ello.
Las actualizaciones de los servidores GNU/Linux se basan en la instalación de los paquetes de actualización mediante autoupdate (56), que es una aplicación de gestión automática de las mismas. Estas actualizaciones se propagan a los clientes cuando se rehace la imagen del sistema raíz (root.tgz) o cuando se utilizan las aplicaciones y librerías actualizados desde el servidor a través de NFS.
Para la actualización de los clientes de Windows XP, hay que recurrir a la aplicación previa de los parches disponibles en uno de los clientes antes de la generación de la imagen cruda con partimage. Aunque se podría realizar la actualización automatizada con el sistema Windows Update, esto sería poco eficiente y obligaría a realizar todas las actualizaciones cada vez que se regenerase el sistema y, lo que es peor, cambiaría el estatus estabilidad y repetibilidad que hemos procurado para las máquinas del laboratorio.
En cualquier sistema informático complejo en el que hay multitud de servidores y clientes, cabe pensar en la necesidad de la creación de un plan de contingencia, es decir, en definir una serie de procedimientos que permitan recuperar la información del sistema completo en diferentes supuestos, a saber:
También se ha contemplado la posibilidad de generar imágenes de reinstalación del servidor principal tanto a disco óptico de arranque (herramienta hazcd) como a fichero (herramienta mkmaestro). A partir de estas imágenes, se puede recuperar el sistema de gestión centralizada con todas sus aplicaciones y datos en pocos minutos. Sin embargo, aunque puede ser muy práctico para generar nuevos dominios de administración (otros laboratorios o redes con gestión independiente), mantener estas imágenes actualizadas en todo momento suele resultar poco viable.
En caso de pérdida de datos, para resolver el problema de la gestión de los datos de usuario, así como para permitir la regeneración del sistema principal completo, es fundamental integrar en el sistema de administración centralizada una buena planificación de backupsc.
En el sistema, se han contemplado dos métodos de backup. El primero de ellos consiste en guardar en cintas de backup todos los datos de cada sistema (hay varios tipos de cintas de backup, siendo la tecnología DAT una de las más baratas y extendidas). A este tipo de backup se le denomina de nivel 0, indicando que es de tipo general y guarda todos los datos que haya en el sistema de ficheros en cuestión. Para realizar este tipo de salvaguardas, utilizamos un dispositivo específico que es capaz de utilizar 6 cintas DAT de forma secuencial, permitiendo enlazar el backup y pasar de una de ellas a la otra. La capacidad de las cintas es variable, dependiendo de la densidad de la cinta empleada, pero resulta recomendable utilizar dispositivos capaces de almacenar al menos 12GB sin comprimir.
El segundo de los métodos consiste en realizar comprobación periódica de los datos (archivos, carpetas, etc) que han cambiado en el sistema de ficheros durante ese período y almacenarlos en un disco duro de una máquina remota. A esta técnica le hemos llamado realización de backups incrementales a disco. Este tipo de backups son de lo más versátil y útil, ya que unen la sencillez y rapidez de la copia de datos a través de la red con la comodidad de tener los datos almacenados en un dispositivo de acceso aleatorio, como el disco duro (en comparación con la utilización de un dispositivo de acceso secuencial, como viene a ser una cinta de backup).
La planificación del sistema de backup es una de las tareas más importantes, dado que debe haber siempre una forma de regenerar los datos del día anterior a la pérdida. Para ello, ambos tipos de backup, los completos y los incrementales, habrán de ser combinados adecuadamente para realizar sus tareas de forma coordinada. Dependiendo de la cantidad de cintas que queramos utilizar y de la cantidad de disco duro para backups de que dispongamos podremos tener más o menos días de salvaguarda.
Los programas utilizados para realizar los backups completos en el laboratorio ha sido dump, mientras que para la realización de los incrementales utilizamos tar. Los ordenadores más críticos para la realización de backups, son aquellos en los que hay usuarios o datos de usuario, dado que la información de las máquinas donde no los hay suele ser menos sensible a pérdidas. Por ejemplo, este es el caso de las máquinas de cuentas (donde se guardan los datos de los alumnos y de las cuentas de prueba de los profesores) y de web (donde se guardan los datos de las cuentas de los profesores y la información consultada por los alumnos para la realización de las prácticas).
Cuando se produce una caída de tensión eléctrica en un ordenador que estaba accediendo al disco para grabar datos, se produce una situación de la que puede resultar una pérdida de los datos que se pretendían grabar, inconsistencia de los mismos en el sistema de ficheros y otros problemas relacionados. Por ello es fundamental dotar a los servidores principales de este sistema de algún tipo de mecanismo que les proteja de este tipo de caídas, de los picos de tensión y de otras fluctuaciones indeseables en el suministro eléctrico.
Este equipo es lo que llamamos un SAI (sistema de alimentación ininterrumpida). Normalmente tiene un puerto serie de control, a través del cual se le pueden enviar comandos o recibir información sobre el estado de las baterías, la carga del sistema y otros datos. Pues bien, este puerto de control ha de estar conectado a un servidor capaz de enviar al resto una orden de apagado o de cancelar dicha orden, en caso de caída del fluido eléctrico o de su vuelta a la normalidad. Este tipo de sistemas permiten mantener la tensión eléctrica durante unos cuantos minutos, tiempo suficiente para que los servidores guarden sus datos correctamente a disco y se apaguen.
Es fundamental para comprobar y planificar el uso de los recursos del laboratorio. Para sacar las estadísticas se usan los registros de acceso tanto de los clientes Windows XP como de los clientes GNU/Linux. En el caso de los clientes Linux, se les configura para enviar a su servidor de arranque los logs (registros) de acceso. Las estadísticas, una vez agrupadas y reformateadas (para adecuarse al formato necesario) se procesan con analog, un programa especializado en contabilizar los accesos a servidores web, que se puede adaptar para realizar la tarea.
Mediante este método, se extraen las siguientes estadísticas:
Para comprobar el funcionamiento de los servicios de forma periódica es conveniente realizar una exploración y un análisis de sus características, su alcanzabilidad y su carga. De esto se encarga un programa también desarrollado localmente llamado lab_servers_info, que mediante la herramienta nmap (58) permite conectarse al puerto de cada servidor con el fin de ver si responde. Es importante reseñar que lo único que se hace es comprobar la respuesta del servidor, sin intercambiar ningún tipo de mensajes ni utilizar el protocolo en cuestión, por lo que la comprobación no da la certeza absoluta al administrador de que el sistema esté funcionando correctamente. Para comprobar la carga del servidor, y la cantidad de disco utilizado y disponible, se realiza un comando remoto con ssh.
Según va recibiendo los resultados, el programa los analiza, estableciendo niveles de alarma si un servicio no está disponible, si la carga es superior a un límite o si la cantidad libre de disco duro no sobrepasa de lo establecido, por ejemplo. Finalmente, se envía un correo al administrador indicando si han detectado o no problemas en el sistema.
Esta utilidad ha demostrado ser más útil que aquellas que utilizan los ficheros de registro (logs) del sistema para comprobar lo que pueda estar sucediendo, debido a que hay muchos problemas que no es posible detectar con este método y a que hay muchos tipos de error diferentes como para gestionarlos todos. Otros problemas añadidos a ese tipo de aplicaciones sería la posibilidad de cambio de los mensajes sin previo aviso y la falta de comprobación de la funcionalidad real del sistema remoto.
En este apartado se pretende ofrecer una visión general sobre las infraestructuras utilizadas para la implementación real del laboratorio y de la configuración empleada para la distribución de los servicios gestionados mediante este proyecto.
Los laboratorios docentes del DIT tienen dos características diferenciales que le han condicionado a la hora del despliegue de infraestructuras de nivel físico (entendiendo por éste, el cableado de comunicaciones utilizado para la implementación de la red de datos). La primera de ellas es que es un laboratorio multipropósito y multisistema, lo que implica que ha de dar servicio a asignaturas muy diferentes y por tanto con necesidades diferentes. La segunda es que el servicio se ha de proporcionar en múltiples aulas de la Escuela Superior de Ingenieros Técnicos de Telecomunicación (ETSIT).
Al darse diferentes necesidades en la actualidad y posiblemente también en el futuro, la infraestructura de red ha de ser correctamente dimensionada ya que, por ejemplo, han de convivir asignaturas que requieren una gran cantidad de recursos a nivel de red (como puede ser el laboratorio de Redes y Servicios Telemáticos) con otras que requieren una gran cantidad de recursos a nivel gráfico, de memoria, de potencia de cálculo, de ancho de banda o de compatibilidad (como podrían ser asignaturas de temática multimedia, de simulación, de bases de datos, de programación avanzada, de sistemas inteligentes o de medidas de eficiencia de red, por citar algunas).
Por todo esto y porque el coste de las infraestructuras a nivel físico no es despreciable con respecto al resto de las inversiones, ha de tenerse en cuenta la capacidad de las mismas y las posibles necesidades en un futuro próximo, a la hora de realizar el despliegue. En el caso de los laboratorios del DIT, debido a la existencia de dos aulas diferentes, se ha decidido utilizar una de ellas para las asignaturas con bajas necesidades a nivel de cableado (laboratorio A.127-2) y la otra para aquellas que requieren altas inversiones en este campo (laboratorio B.123).
Así, el aula B.123 dispone de todo el equipamiento necesario para realizar las asignaturas prácticas que tienen grandes necesidades de infraestructura. Es capaz de funcionar independientemente del otro laboratorio (el A.127-2) y todos sus ordenadores pueden utilizarse tanto en Windows XP como en GNU/Linux, dependiendo de la asignatura y de la práctica que el alumno pretenda realizar. Cada ordenador cliente tiene acceso al menos a 3 redes diferentes mediante cableado estructurado, que en su totalidad es de alta capacidad de transmisión de datos (categoría 6+ o Gigaspeed) pudiendo ofrecer servicios de hasta 1 Gbps. Este cableado se utiliza específicamente en los laboratorios de redes, permitiendo realizar múltiples configuraciones en todos los niveles de comunicación. En la figura 5.3 se muestra la estructura general de este laboratorio.
Hay que mencionar también que debido a las características especiales de la instalación eléctrica de los diferentes edificios en los que se tienen aulas de laboratorio (por estar suministrados por compañías eléctricas diferentes), es necesario interconectarlos mediante fibra óptica, tal y como se indicará en la sección 5.1.2. Además, para el mantenimiento, gestión y rendimiento del cableado es necesario realizar una buena administración del cableado horizontal, siguiendo una norma estandarizada (en nuestro caso, la EIA-568-B) para la conectorización y distribución del cableado, la utilización de patch panelsa y la asignación de ubicaciones específicas para estas tareas. Para ello no sólo es imprescindible el conocimiento de la normativa y las características del cableado sino también el disponer de personal capacitado para realizar las tareas de administración, configuración, pruebas y mantenimiento del mismo.
El nivel de enlace se ha construido mediante el despliegue de una red Ethernet interconectada mediante enlaces de gigabit-ethernet. Es muy conveniente utilizar como mínimo este ancho de banda para asegurar que hay ancho de banda disponible suficiente como para satisfacer las necesidades de comunicación de todos los servicios desplegados de forma simultánea. La solución está basada en equipos conmutadores ethernet de alta velocidad de conmutación, con múltiples velocidades por puerto, con puertos de interfaz física diferente (fibra óptica monomodo, fibra óptica multimodo y par trenzado no apantallado) y con capacidad de gestión de redes virtuales de área local.
Estos conmutadores, están configurados de tal modo que todos los puertos de una misma red IP comparten una misma red virtual de área local (o VLAN (48)) lo que significa que a nivel de enlace usan un único dominio de broadcast. Además, todos los puertos de los conmutadores son full-duplex, lo que implica que todos los ordenadores conectados a conmutadores tienen la posibilidad de transmitir y recibir datos a la vez, por dos canales independientes y sin posibilidad de colisiones. Esta característica nos permite hacer la red del laboratorio tan grande como sea necesario y además dar un servicio ethernet de gran capacidad a los clientes.
Esta tecnología, además permite configurar un ordenador en varias VLAN (si son capaces de utilizar el protocolo 802.1Q) realizando lo que se llama ''multihoming'', de tal forma que podría hacer routing entre ellas sin necesidad de utilizar varias tarjetas de red. También es posible cambiar un servidor de VLAN (incluso de forma automática) sin necesidad de tocar el cableado, lo que aparte de ser mucho más cómodo resulta también mucho más fiable, puesto que la manipulación física del conexionado suele ser la que más problemas provoca en este tipo de entornos.
Como se ve en la figura 5.4 los servidores están directamente conectados al conmutador central y situados en el Centro de Cálculo del DIT (CDC). Cada uno de ellos se conecta mediante enlaces de 100 Mbps full-duplex de par trenzado sin apantallar, aunque está planificado aumentar el ancho de banda de algunos de los servidores a 1 Gbps en un futuro próximo para aumentar el rendimiento (como puede ser en el caso del servidor de disco de red).
A nivel de red, el laboratorio está dividido en dos redes IP independientes, unidas entre sí por un router/proxy y llamadas LABnet (la interna) y ADMnet (la externa). Además de estas dos redes, que a nivel físico son Fast-Ethernet, también se han creado otras redes basadas en otras tecnologías (Frame Relay, Ethernet, ATM o RDSI) que, con un direccionamiento IP privado (192.168.0.0/16) permiten la realización de las prácticas de Redes y Servicios Telemáticos.
Como se puede observar en la figura 5.6, la red interna (LABnet) es la red del laboratorio donde están situados:
En ADMnet se han situado los servidores públicos del laboratorio, que gestionan los servicios que el laboratorio ofrece a través de Internet, como son el web, el correo electrónico, el DNS, etc. En la figura 5.6 se puede ver que en ella están:
El sistema de administración centralizada ha de solventar los diversos problemas de gestión que se han planteado y discutido en los anteriores capítulos. Aunque la solución para cada uno de ellos puede ser diferente en muchos aspectos, este proyecto ha extrapolado las partes comunes y pretende ofrecer un punto de vista integrador a partir del cual desarrollarse de forma sostenible. Así, se ha hecho hincapié en la utilización de las facilidades de conectividad en red de los equipos administrados y en gestionarlos con procedimientos automáticos y desatendidos en la medida de lo posible.
En lo que queda de capítulo, se pretende ofrecer al administrador y al evaluador de este sistema un punto de vista mucho más detallado de las vías de resolución adoptadas, para que sea posible, no sólo compararlo con otros sistemas similares, sino también para que sea más sencilla la adaptación al mismo de nuevos los usuarios o administradores y para facilitar la integración de este proyecto con otros futuros que puedan ampliarlo, modificarlo o simplemente utilizarlo.
Como se ha comentado anteriormente (sección 4.6), el sistema de administración centralizada está dividido jerárquicamente en tres niveles, siendo el nivel superior (servidor principal o maestro) el que implementa el sistema de administración centralizada propiamente dicho, delegando las subtareas básicas al nivel inmediatamente inferior (servidores secundarios). En el último nivel jerárquico están los clientes de laboratorio que son el punto de acceso a los servicios del laboratorio y donde el usuario final accede y se autentica.
El servidor principal del sistema de administración centralizada del laboratorio (maestro) tiene la función primordial de ser el gestor del resto de los servidores del laboratorio, que se instalan a partir de las configuraciones y servicios que él proporciona. También es el ordenador donde el operador y el administrador realizan sus tareas de configuración y administración, no dando servicio a ningún otro usuario del laboratorio de forma directa.
Los servidores que se ejecutan en maestro son:
Los servidores secundarios de arranque (también llamados binarios) están integrados en el sistema de administración centralizada y hacen uso de las facilidades creadas para la instalación, gestión y actualización de servidores GNU/Linux. Estos servidores tienen como tarea principal permitir el arranque y la configuración de los clientes del laboratorio que hacen uso de sus diferentes servicios:
Tanto los binarios como el resto de los servidores secundarios son máquinas que el administrador no ha de gestionar manualmente, puesto que esa labor la realiza el sistema de administración centralizada implementado. Así, por ejemplo mediante éste se programa el servicio de cron para realizar las actualizaciones automáticamente o para reiniciar el sistema de forma periódica. También está programado el rotado de los ficheros de registro para evitar una utilización excesiva del disco duro.
Mientras que las necesidades de los servidores secundarios multipropósito dependen del servicio o servicios que proporcionen a la red, los requisitos de los ordenadores que se quieran utilizar como binarios se pueden concretar en los siguientes:
Son los ordenadores finales del laboratorio y por tanto los que dan servicio de forma directa al usuario. En los laboratorios del DIT tienen dos posibles tipos de sistema operativo: GNU/Linux y Windows XP Pro. La elección del sistema operativo se realiza a través de un menú que se muestra al iniciarse el sistema. En él se le permite al usuario elegir entre:
En el caso de la carga Linux, se hace la reinstalación cada vez que el usuario quiere utilizarlo, debido a que el proceso completo tarda muy poco tiempo y a que los sistemas de ficheros utilizados (ext2) son muy sensibles al apagado brusco del ordenador. Por esta razón, los sistemas de ficheros utilizados en Linux se formatean cada vez que se reinstala, con lo que conseguimos un proceso de instalación muy estable. Esto nos da una ventaja añadida: tal y como está concebido el sistema, no pasa nada si el ordenador se apaga sin sincronizar los discos (sin guardar los datos que puedan estar en el caché), cosa que ocurre por ejemplo, cuando se corta de forma súbita el suministro eléctrico del aula.
La regeneración de Windows XP no se puede realizar cada vez, ya que implica demasiado tiempo de espera (en relación con el tiempo de un turno de trabajo, que es de dos horas), así que hemos dejado que sea el propio usuario quien decida si necesita o no regenerar el Windows XP del ordenador que está utilizando. Esta técnica suele ser bastante adecuada, debido a que no sólo permite ahorrar tiempo, sino también recursos de red. En el caso de un apagado brusco del sistema, el XP es bastante más sensible que Linux y puede obligar al usuario a la regeneración.
Sea cual sea el sistema operativo utilizado por el cliente, se utiliza un sistema de disco a través de red para almacenar sus archivos (en Linux se usa NFS, mientras que en Windows se usa NETBEUI). Esto asegura la integridad de la información del usuario del laboratorio casi en cualquier circunstancia, ya que el ordenador de acceso no se utiliza más que como mera herramienta de trabajo y para almacenar datos temporales. Como se ha mencionado con anterioridad, el correo también reside en un servidor remoto, así como los perfiles de usuario. Esto permite que la configuración de escritorio (o entorno de trabajo personal) de cada usuario sea siempre la misma, independientemente del cliente en el que esté trabajando.
El sistema de administración centralizada consiste en un conjunto de utilidades que gestionan la información de configuración almacenada en una base de datos. El sistema se puede operar desde la línea de comandos, estando previamente registrado en el sistema como administrador o como operador (dado que ambos roles tienen funciones diferentes).
Aunque todas las estaciones de una red son diferentes entre sí en muchos aspectos (nombre, dirección IP, dirección MAC, etc) también tienen entre ellas muchas cosas en común. Sobre todo, cuando comparten el mismo sistema operativo, tienen el mismo hardware o realizan la misma función. Para estos casos, la configuración de una estación es una instancia de un modelo.
Llamamos modelo a una lista ordenada de patrones, siendo los patrones un conjunto concreto de archivos y utilidades del sistema que están parametrizados con variables del sistema de administración y que permiten configurar un servicio o una aplicación.
Así, por ejemplo, si una estación dispone de una tarjeta RDSI, se creará un patrón que gestione su configuración a nivel de dispositivo, la instalación de las aplicaciones implicadas en su funcionamiento y las configuraciones necesarias para éstas.
En cada patrón, se definen variables que permiten independizar la gestión de un servicio de la máquina concreta a la que se aplica. Las variables de un patrón se introducen como propiedades en la base de datos de configuraciones. Las estaciones que utilicen un modelo que incluya un patrón determinado deben tener asignados valores concretos para esas variables en la base de datos.
En la versión actual del sistema, los patrones son directorios, que reproducen a su vez la estructura de directorios desde el raíz del sistema de ficheros de la estación que los utilizará. Es decir, si en un patrón determinado, se quiere configurar un fichero que está debajo del directorio etc (por ejemplo el /etc/resolv.conf), el directorio del patrón tendrá un subdirectorio llamado etc y, dentro, el fichero que se quiere configurar (resolv.conf).
Este fichero podría estar almacenado en el patrón en formato final, es decir, tal y como sería capaz de utilizarlo la estación que lo necesita, pero eso obligaría a tener un patrón por cada estación que necesitase ese fichero con valores diferentes. Lo que le da valor añadido al sistema de patrones es que en ese fichero, puede haber nombres de variables, que se sustituirán en el proceso de configuración a partir de la información contenida en la base de datos.
Los patrones están pensados de tal forma que actúan como una transparencia sobre el sistema de ficheros de la estación que los utiliza, permitiendo su superposición. De esta forma, diferentes patrones pueden afectar a los mismos archivos de la estación a configurar, prevaleciendo los cambios que haya realizado el último de los patrones en aplicarse. Esta característica permite realizar configuraciones complejas y muy versátiles, que pueden sacar el máximo partido a la configuración de cada modelo de estación.
Todas las estaciones de una red pueden clasificarse según su configuración. Esta característica es la que aprovecha el sistema de patrones, que permite catalogar en modelos de estación las diferentes configuraciones de un modo extensible.
En resumen, los patrones son conjuntos de archivos parametrizados de un componente o de una utilidad. La configuración que finalmente se instala en la estación es el resultado de acumular todos los patrones del modelo elegido y sustituir los valores de las variables que aparecen en los ficheros de configuración.
Así, para el caso anterior de la configuración del servicio de nombres de una estación particular a través del fichero /etc/resolv.conf, se podrían definir dos variables (o propiedades) AC_NAMESERVER y AC_DNS_SEARCH que serían sustituidas por los valores almacenados en la base de datos para esa estación en concreto (ver figura 5.11). Añadir el prefijo AC_ al nombre de cada una de las variables, tiene como objetivo el diferenciarlas de otras posibles variables no gestionadas con el sistema de Administración Centralizada.
Cuando se construye la configuración de una estación determinada, se sustituyen las variables de cada fichero patrón por los valores definitivos para esa estación, según se indique en la base de datos (ver figura 5.12). Para realizar esta operación de transformación, se han desarrollado unos scripts basados en la utilidad m4 de GNU (16), disponible para todas las distribuciones de GNU/Linux. m4 se invoca con dos parámetros principales: el archivo que contiene la definición de variables (que estará en la base de datos) y el archivo a transformar (que estará en el directorio de patrones). El resultado es el archivo particularizado para una estación con los valores de las variables sustituidos.
La base de datos está organizada en diversos ficheros de texto, cada uno de ellos con sus definiciones de variables m4 (que también llamamos propiedades). A su vez, están distribuidos en directorios, que los clasifican según el componente que definan, por debajo del directorio bdm (acrónimo de ''base de datos de máquinas'').
Por ejemplo, si el componente es la tarjeta VGA, habrá diferentes ficheros con las definiciones de variables para las diferentes tarjetas de ese tipo. Así, tendremos un fichero ati.m4 para las definiciones de variable correspondientes a la tarjeta de video ATI, y otro llamado s3.m4 para las definiciones de variable correspondientes a la tarjeta de vídeo S3. Ambos archivos estarán bajo el subdirectorio vga del directorio bdm.
El perfil de una máquina determinada, se genera a partir de los ficheros concretos de los diferentes componentes que la forman (tarjeta vga, tarjeta de red, tarjeta de sonido, etc), mediante la inclusión de los archivos m4 correspondientes para cada uno. Por tanto, un perfil es un conjunto de ficheros de definición de variables m4 agrupados mediante la técnica de inclusión, en uno de mayor rango.
Los componentes de una estación no tienen porqué ser sólo definiciones de configuraciones hardware, sino que también pueden consistir en la definición de las variables o propiedades del software que se pretenda configurar en ella. Así, por ejemplo, se podría incluir en la definición del perfil de una máquina el fichero de la base de datos que mostramos en la figura 5.12, que quedaría tal y como se muestra en la figura 5.14.
Como cabe esperar, todos los componentes de un mismo tipo, han de definir las mismas propiedades, aunque cada componente concreto pueda tener un valor distinto para cada una de esas propiedades. Además, cada propiedad ha de tener el mismo nombre que la variable que pretende sustituir en los patrones definidos, así, si hay una variable AC_NAMESERVER en alguno de los ficheros de configuración de los patrones, debe existir una definición para esta variable en alguno de los ficheros de componentes de la base de datos, y este fichero habrá de ser incluido en el perfil de la máquina que lo pretende utilizar.
Por lo tanto, como resumen, podemos indicar que la base de datos de máquinas se basa en tres conceptos diferentes: el de propiedad (como definición de una variable), el de componente (como un conjunto de propiedades definidas de forma específica) y el de máquina o perfil de máquina (como un conjunto de componentes integrados).
A diferencia de otros sistemas de administración, éste no establece ninguna propiedad por defecto. El administrador define la lista de propiedades a medida que va genera los nuevos patrones según sus necesidades. Por esta razón, el esfuerzo de despliegue de la red es mucho mayor al principio que cuando la red ha crecido suficientemente.
La gestión de esta base de datos basada en ficheros, aunque ofrece una gran funcionalidad, no es tan sencilla como sería conveniente, puesto que el administrador debe editar los ficheros manualmente y puede cometer equivocaciones a la hora de nombrar o dar valores a variables y ficheros. Por eso, están en desarrollo un interfaz gráfico y una base de datos relacional que ayudarán al administrador a crear propiedades, componentes y perfiles nuevos y a modificar los ya existentes.
La herramienta del sistema de administración centralizada que generará el ks.cfg en función del perfil de cada máquina se llama mkdist. A mkdist se le pasa como parámetro el nombre del perfil de la máquina (nombremaq.m4) con el que se genera el archivo de instalación desatendida (ks.cfg) y un fichero que incluye todas las propiedades de la máquina concreta que se definieron en la base de datos. Este archivo que llevará el mismo nombre que el perfil, se guardará localmente bajo el directorio distrib/redhat-7.3/maquinas/nombremaq y se transmitirá a la máquina para que, en un proceso posterior de configuración (autoactualiza), disponga localmente de los valores de todas sus variables AC.
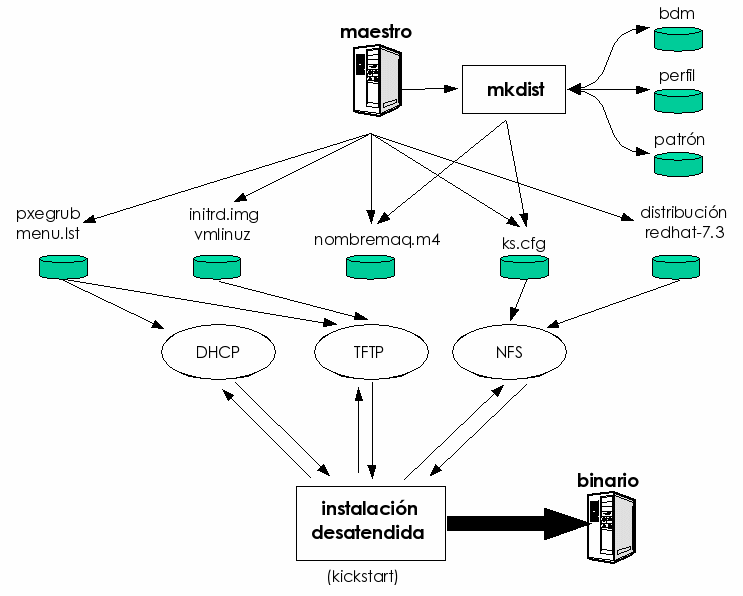
|
Tal y como se explicó en la sección 4.6.1, los servidores a instalar deberán estar configurados para el arranque por red. Las configuraciones particulares para cada servicio implicado se generarán también de forma automática a partir de la herramienta de gestión de DHCP y DNS que forma parte del sistema central del DIT (install.hosts), para más detalles véase también el punto 6.3.9.
En la fase de postinstalación del sistema operativo, se configura la estación para que en su primer arranque ejecute la herramienta autoactualiza. Esta aplicación permite realizar cambios genéricos de los archivos instalados localmente, según lo especificado en los patrones del sistema de administración centralizada (previa transformación de los mismos en base al perfil de la máquina concreta). Además, ejecuta procedimientos que, entre otras cosas, permiten la instalación de paquetes no estándar y pueden programar a través del cron diversas tareas de carácter periódico (como puede ser la actualización de los paquetes instalados, ejecución de backups, rearranque, chequeo de cuotas, etc).
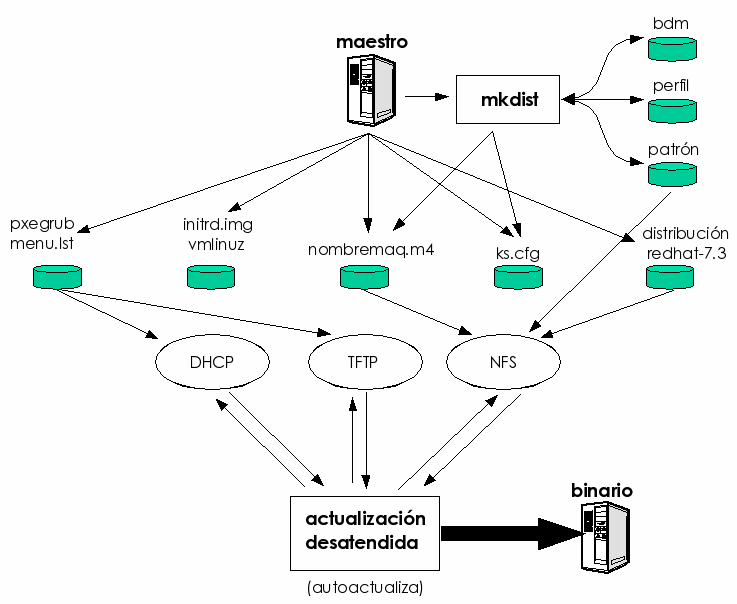
|
Como se puede intuir por la cantidad de cosas mencionadas, la herramienta autoactualiza es la que más valor añadido proporciona al sistema de administración centralizada, ya que está diseñada para permitir la gestión automática de cualquier parte del software del sistema administrado.
Este proceso en conjunto, aunque quizá resulte muy complejo de comprender, es sin embargo muy rápido, permitiendo instalar y configurar un servidor completo en muy pocos minutos.
En nuestro caso, el fichero root.tgz está generado con tar y comprimido con gzip. Para gestionar este tipo de imágenes de forma automática, hemos creado un script llamado mkroot.
Una vez se ha creado el fichero root.tgz, hemos de distribuirlo a los servidores de arranque de los clientes. Para realizar la tarea de distribución se ha configurado la herramienta rdist en el directorio imagenes_rdist del servidor de administración.
El fichero root.tgz, base del sistema operativo local que se instala en el cliente, no contiene todos los archivos necesarios para el sistema local. Esto es así para evitar que haya que transmitir un archivo root.tgz demasiado grande cada vez que se quiere instalar el ordenador. Podemos decir que en el fichero mencionado se transmite únicamente la información básica, mientras que el resto de la información, que será necesaria para el usuario, se comparte con el servidor desde el que se realiza la instalación. En nuestro caso concreto, esta compartición se realiza mediante protocolo NFS en modo de sólo lectura y da una ventaja añadida al sistema y es que cuando se actualiza una aplicación que el cliente recibe por NFS, automáticamente el cliente tiene disponible la versión actualizada.
Esta concepción de compartición de ficheros a través de la red la hemos utilizado no sólo para los archivos de aplicación (normalmente debajo del directorio /usr), sino también para las librerías dinámicas del sistema (/lib), y las aplicaciones generales y de administración (que están en /bin y /sbin, respectivamente). Incluso los archivos de configuración del sistema gráfico o de los usuarios y grupos del sistema se comparten de esta manera, de tal forma que no es necesario reiniciar la máquina o realizar ningún proceso específico para permitir que en un cliente del laboratorio haya una nueva cuenta de alumno disponible.
Las tareas previas a la de descompresión del fichero root.tgz incluyen la gestión del disco duro donde se expandirá y otras pequeñas tareas que habrán de ser realizadas sin necesidad de disco duro (como configurar el interfaz de red, por ejemplo). El núcleo de Linux nos ofrece la posibilidad de crear un disco virtual a partir de la memoria RAM del sistema. Este disco se transmite a través de la red en tiempo de arranque y de forma consecutiva a la del núcleo. Una vez recibido en la máquina cliente, se pasa control al núcleo que a su vez es capaz de expandir la imagen recibida (de tipo especial) y cargarla en memoria como un disco. Hecho esto, busca en ese disco especial un programa de inicio (linuxrc) y lo ejecuta. A partir de aquí, el cliente comienza a gestionarse a sí mismo gracias a la inteligencia dotada a los scripts incluidos en esa imagen. La característica del núcleo capaz de gestionar estos discos virtuales se llama initrd y hay amplia información sobre ella en todo tipo de foros de administración de Linux en Internet. La herramienta creada por nosotros para gestionar este tipo de imágenes se llama mkimagen y permite actualizar los módulos del kernel de una imagen determinada, cambiar sus archivos, redimensionarla y gestionar sus scripts de arranque con bastante sencillez.
Para minimizar el uso de la red en tiempo de arranque, hemos diseñado un programa (rc.checkfile_hda4) que es capaz de gestionar una partición del disco como caché, comprobar si existe el archivo necesario (en este caso el root.tgz), descargándolo en caso contrario, y asegurarse de que la copia descargada es correcta mediante la utilización de un algoritmo de firma de ficheros (md5sum).
Desde el punto de vista del usuario, la opción que ha de elegir para reinstalar el cliente con GNU/Linux es la de ''Instalación y Arranque de GNU/Linux''. Describimos a continuación los pasos intermedios realizados en el ordenador cliente cuando se ejecuta esta opción:
La regeneración de Windows XP, desde el punto de vista del usuario, se realiza en dos subfases: regeneración cruda y autoconfiguración. Los pasos intermedios son los que pasamos a describir a través de las opciones que se le ofrecen al usuario mediante el menú descargado de la red:
Terminado el proceso de autoconfiguración, se reiniciará automáticamente el sistema. El proceso de reinicialización después de la autoconfiguración es inevitable con este sistema operativo.
En algunos entornos puede resultar conveniente que este sistema operativo esté configurado para unirse a un dominio a través del cual gestionar los usuarios de forma remota y también para permitirle la utilización de un disco de red. Tanto la gestión del dominio como la del disco de red se realizan a través de un servidor GNU/Linux que tiene debidamente configurado un servidor SAMBA (25) con SSL que permite encriptar las conexiones de datos. Resulta necesario destacar que la interacción de servidores GNU/Linux y Windows XP a través del protocolo NETBEUI es una tarea no exenta de dificultades (27).
Además de la configuración mencionada es necesario administrar los identificadores y las claves de cada usuario y también la cantidad permitida de uso del disco de red (cuotas). En nuestro caso, el sistema de administración centralizada ha de encargarse también de estas gestiones (que se mencionarán en la sección 4.7.1).
Desde el punto de vista del administrador, y dadas las características específicas de este sistema operativo, será necesario crear una imagen particular para la regeneración de cada uno de los tipos de cliente. La creación de la imagen de regeneración de Windows XP se realiza con el mismo programa que se utiliza para la regeneración: partimage. Los detalles de esta tarea se facilitan en la sección 6.2.6, dentro de la especificación de las funciones del administrador.
La instalación de Windows XP de forma automática y desatendida se basa en la configuración de un disquete de arranque que permite al ordenador iniciar su dispositivo de interconexión a la red. El proceso está dividido en varias fases. Primero, se realizará un arranque de disquete y una configuración del dispositivo de red, hecho esto, se montará el servidor de red correspondiente. Luego, se realizará el particionado y la configuración del disco duro local a partir de ciertos archivos de red. Hasta aquí la fase MS-DOS. Más tarde se realiza una instalación desatendida de Windows XP a través de la red (fase Windows), y para finalizar, se instalan las aplicaciones extra para el sistema operativo (fase Aplicaciones).
Para iniciar este proceso necesitaremos un ordenador que cumpla los requisitos mínimos para la instalación de Windows XP, requisito trivial pero no fácil de satisfacer, debido a la gran cantidad de recursos necesarios en el PC (mínimo 256MB de RAM e Intel Pentium III CPU) para la utilización satisfactoria de este sistema operativo. Además, la BIOS habrá de estar configurada para ser capaz de iniciar la estación desde los archivos contenidos en un disquete de arranque (o en un CD-ROM en su defecto, creado con las utilidades isolinux y memdisk (9)). Por sencillez, el proceso que se relatará en esta sección está referido únicamente a la utilización de un disquete.
Como es obvio, el ordenador que se pretenda instalar habrá de tener espacio suficiente en el disco duro para albergar el nuevo sistema operativo y sus aplicaciones. Además, este espacio habrá de estar disponible de forma contigua.
Esta fase consta a su vez de dos partes. La primera permite el particionado del disco local, mientras que en la segunda se inicia la instalación de Windows XP.
Mediante un disquete MS-DOS con soporte de red (creado con las utilidades proporcionadas por Bart Lagerweij desde su página web (60)) se arranca el cliente. En el proceso de arranque, este disquete analizará sus dispositivos, identificará su tarjeta de red, cargará sus drivers, utilizará DHCP para averiguar su dirección IP y nombre (nombremaq) y después montará mediante protocolo NETBEUI un directorio de una máquina remota (el servidor principal o uno de los servidores secundarios).
En ella (a esta unidad la hemos llamado z:), estarán ubicados los comandos necesarios para realizar las tareas de preparación del disco local (nosotros hemos llamado a este archivo nombremaq.bat) y los archivos necesarios para la instalación de Windows XP. También se monta otra unidad de red (con permiso de escritura) para guardar archivos temporales (a esta unidad la hemos llamado y:).
Hecho esto, se busca en la unidad z: el archivo de comandos nombremaq.bat y con él se particiona y formatea en FAT-32 el disco duro a través de la aplicación aefdisk (40). Hay dos opciones: o que todo el disco duro esté disponible o que sólo lo esté una parte de él (en una partición). En cualquier caso, el archivo nombremaq.bat habrá de estar correctamente configurado para gestionar la parte implicada. Al finalizar, se crea en el disco temporal un archivo con el nombre de la máquina que servirá para indicar que ya se ha realizado la configuración del disco local. Después, se reinicia el ordenador.
La segunda subfase arranca también con el disquete MS-DOS que hemos utilizado antes. Esta vez, el archivo de ejecución por lotes (autoexec.bat) que se inicia al arrancar no sólo configura la red y monta las unidades remotas, sino que comprueba si existe el fichero temporal que indicaría que ya se ha realizado la primera subfase y que hay que proceder a realizar la segunda. Ésta consiste en borrar el archivo de estado, ejecutar el comando de instalación de Windows XP desde la unidad de red y finalizar el proceso con un nuevo rearranque.
Para llevar a cabo la instalación de Windows XP desde la unidad de red de forma desatendida, es necesario ejecutar el comando de instalación pasándole como parámetro el fichero de configuración nombremaq.txt que previamente habremos preparado. Este archivo, que Microsoft en su documentación denomina unattend.txt, se puede crear con una utilidad llamada setupmgr que encontramos en el disco de instalación de Windows XP dentro del fichero support\tools\deploy.cab.
En nuestro caso, nombremaq.txt se encarga de indicar a la aplicación de instalación las respuestas a las preguntas de la instalación. Las indicaciones son, por ejemplo, que queremos convertir el sistema de ficheros a NTFS (para que se puedan gestionar permisos de acceso a los ficheros), cuál será el identificador y la clave del administrador del sistema, la licencia de producto, etc. Además, en este fichero también se especifica el nombre del script que permitirá realizar la instalación de aplicaciones una vez se haya realizado la instalación del sistema operativo (en lo que es realmente la postinstalación). En nuestro caso, hemos llamado a este último script nombremaq.cmd.
En concreto, el comando de instalación que se ejecuta es z:\winxp\i386\winnt /s:z:\winxp\i386 /u:z:\WINXP\MAQUINAS\nombremaq\nombremaq.txt. Este comando, al ejecutarse, realiza la preinstalación del sistema para que el disco duro sea capaz de iniciar la instalación propiamente dicha, objeto de la siguiente fase. Durante la preinstalación, se copia el contenido del directorio winxp\i386 de la unidad z: a la unidad de disco formateada anteriormente mediante el comando aefdisk y que tomará como nombre unidad c:. Después, se configura el sistema para continuar la instalación desde disco duro y se reinicia de nuevo.
Para iniciar esta fase hay que quitar el disquete de arranque (o el CDROM en su caso) y dejar que el ordenador arranque de disco duro, ya que el proceso de preinstalación de Windows XP habrá configurado el sistema para el arranque local. Después de convertir la partición a formato NTFS, se inicia la instalación propiamente dicha, ya con el interfaz gráfico estándar.
Este proceso, al haberlo indicado así en el fichero de configuración nombremaq.txt, será totalmente desatendido, y por tanto no será necesario que permanezcamos delante de la pantalla de instalación. También será capaz de instalar los controladores de dispositivo que no estén incluidos en la distribución siempre que se lo hayamos indicado así en el fichero nombremaq.txt y realizará de forma automática la detección y la configuración del hardware, así como la instalación de la licencia y de todos los archivos y configuraciones del sistema operativo.
Tras la instalación del sistema operativo, el ordenador vuelve a reiniciarse, manteniendo montadas las unidades de red utilizadas en la preinstalación. La siguiente tarea, si así se le indicó previamente, será ejecutar el script nombremaq.cmd (que tiene su propia nomenclatura) como usuario administrador. Este archivo lo utilizamos para dar de alta los usuarios locales, modificar el registro con los parámetros convenientes e instalar las aplicaciones a partir de sus correspondientes ficheros de instalación (que también estarán en la red y habrán de ser instalables de forma desatendida).
Para disponer de más información sobre el proceso, detalles y recomendaciones se puede consultar la documentación preparada por Pedro J. Pérez (62) y la de Karl Bernard (61). También se puede encontrar información sobre la generación de instalaciones de aplicaciones automatizables para Windows en las páginas de Autoit (23) y WinstallLE (39) de Veritas, así como en Microsoft (18) (formato msi).
El primer trabajo que habrá de afrontar el administrador será la instalación del servidor principal y la implantación en el mismo del sistema de administración centralizada. Esta tarea se realizará en varias fases, que describiremos a continuación.
/home/admin/distrib/redhat-7.3: en este directorio se copiará el contenido de los CDs de instalación de la distribución de GNU/Linux, respetando los subdirectorios del sistema de administración particularizados para esta distribución que existan por debajo del mismo.
/home/admin/distrib/redhat-7.3/updates: aquí se deben almacenar los paquetes de actualización de la distribución.
/home/admin/distrib/winxp: aquí se guardará el contenido de los directorios docs, I386, support y valueadd del disco de instalación de Windows XP Professional.
/home/admin/distrib/winapps: aquí se almacenan las diferentes aplicaciones con sus instaladores automáticos y sus archivos de instalación, cada una en su propio directorio. Entre ellas puede estar el Office XP, por ejemplo, en el subdirectorio officexp. A estos directorios accederá el archivo de ejecución de la postinstalación, nombremaq.cmd.
Entre otras cosas, habrá que generar los perfiles de instalación de los servidores secundarios GNU/Linux (nombremaq.m4) y los archivos de configuración correspondientes para la instalación de estaciones Windows XP (nombremaq.{bat, txt, cmd}), así como las imágenes de reinstalación de los clientes GNU/Linux (root.tgz) y de regeneración de los clientes Windows XP (xp.gz.000). Para ello, el administrador habrá de familiarizarse con las herramientas implementadas y con la estructura de directorios del sistema que deberá manejar.
Como explicamos anteriormente, consideramos perfil de una máquina, a un fichero que contiene la localización de los ficheros m4 en los que residen las variables necesarias para su instalación y postinstalación. Para crear o modificar un perfil nuevo, el administrador del sistema debe asegurarse de que existen en la base de datos los componentes particulares para el hardware y software de la máquina en cuestión. En caso de no existir, habrá que añadirlos a la base de datos.
Cuando el perfil está preparado, lo único que resta hacer es ejecutar mkdist, pasándole como único parámetro el nombre del perfil en cuestión. Este comando genera el fichero de texto que permite la ejecución de la instalación desatendida con Kickstart (ks.cfg), coloca este fichero en un lugar de red accesible para el instalador y crea una imagen de disquete por si la estación no puede arrancar de red. También prepara algunos ficheros que serán usados durante la fase de postinstalación para ajustar detalles del sistema.
Los clientes GNU/Linux del laboratorio, una vez que cambian el sistema de ficheros raíz al disco duro, comienzan a arrancar como un ordenador normal con RedHat 7.3. Inicializan los servicios que estén configurados para el runlevel de inicio (actualmente el 5: registro en consola gráfica) a través de lo extraído del root.tgz, y por último ejecutan el script de inicialización local (contenido en el archivo /etc/rc.d/rc.local).
Tal y como está configurado el cliente, el archivo rc.local es un enlace al archivo /usr/local/local/clients_conf-1.1/etc/rc.d/rc.local del servidor binario que le ha proporcionado el arranque. Con él, se analiza el archivo dispositivos (también accesible por NFS), se extrae el perfil concreto del cliente y se configuran con él las aplicaciones dependientes de los mismos: el gestor de ratón (gpm) y el servidor gráfico (XFree (63)).
Para ver cómo modificar el archivo dispositivos, se puede consultar el apartado 6.3.10. Para modificar el fichero rc.local, aunque es necesario tener conocimientos de programación en shellb, se debe utilizar exactamente el mismo procedimiento de distribución.
Todos los clientes GNU/Linux utilizan el mismo servidor gráfico y el mismo fichero de configuración (/etc/X11/XF86Config-4, que también se obtiene por NFS), aunque sus dispositivos sean diferentes. La distinción se realiza al ejecutar el rc.local, especificándole al sistema gráfico el perfil concreto para la máquina en cuestión. Para ello, hay que utilizar el parámetro -layout seguido del nombre que agrupa la configuración concreta del cliente y guardar esa información en el archivo de configuración del sistema gráfico /etc/X11/xdm/Xservers, tarea que también realiza el propio rc.local.
Por eso, cuando se modifica el archivo /usr/local/local/clients_conf-1.1/lib/X11/XF86Config-4 de maestro y se distribuyen los cambios a los binarios, no se actualiza automáticamente la configuración de los clientes hasta que se reinician o se ejecuta localmente en cada uno de ellos el script rc.local.
Cuando se desee añadir un nuevo tipo de cliente GNU/Linux, la modificación del fichero de configuración del servidor gráfico habrá de hacerla un administrador del sistema teniendo en cuenta las capacidades físicas del monitor y la configuración del resto de los dispositivos.
Como se ha explicado en la sección 5.2.3, los clientes de Linux utilizan un disco virtual en memoria RAM (initrd) para las tareas de inicialización de sus dispositivos y configuración del disco duro local con el fin de instalar en él el sistema operativo GNU/Linux. Dado que en el initrd se almacenan los módulos del núcleo (vmlinuz) relativos a la gestión del hardware, y que éstos son diferentes cuando cambia la versión, el initrd habrá de modificarse siempre que se decida actualizar la versión del núcleo.
Para una gestión más sencilla del initrd de los clientes del laboratorio, se ha creado el programa mkimagen. Este script, se ejecuta en el servidor de administración y a través de él se puede desempaquetar y volver a empaquetar de forma automática el archivo initrd especificado.
Las tareas más comunes de gestión de este disco virtual consisten en la realización de los cambios necesarios para actualizar la versión de algún módulo de vmlinuz o para modificar la configuración del sistema durante el arranque (a través del script /linuxrc del ramdisk). Explicaremos brevemente la forma de proceder para la realización de estos cambios.
cd /home/operador/administracion/servicios/arranque_maquinas
NOTA: Por abreviar, en esta sección, indicaremos el acceso a este directorio refiriéndonos únicamente a arranque_maquinas.
./mkimagen -i -e linux-ntfs
En este caso, como deseamos modificar la imagen de disco RAM de Linux que se carga en los clientes GNU/Linux, utilizamos el parámetro linux-ntfs. Con este parámetro se le dice al programa que utilice la imagen que recibe como nombre completo initrd.img-linux-ntfs.
Al arrancar el programa, éste muestra una serie de mensajes indicando que está desempaquetando la imagen y muestra el directorio en que la pone accesible (arranque_maquinas/mount_points/nueva). Asimismo, queda a la espera de una pulsación de [ENTER] para volver a empaquetarla desde ese mismo directorio.
cd arranque_maquinas/mount_points/nueva/lib/modules/current
cp /lib/modules/<version>/kernel/drivers/net/eepro100.o .
cd arranque_maquinas/mount_points/nueva
vi linuxrc
cp linuxrc arranque_maquinas/scripts/linuxrc.<fecha>
Para seguir una norma, especificamos la <fecha> empezando por las dos últimas cifras del año, siguiendo por el número del mes y terminando con el número del día dentro del mes. Ejemplo: el 16 de Abril de 2003 se indicaría como 030416. Este formato tiene una pequeña ventaja y es que la ordenación numérica de los archivos coincidiría con la ordenación temporal.
cd arranque_maquinas
cd arranque_maquinas/tftpboot
make rdist
Para minimizar la cantidad de imágenes necesarias para las diferentes configuraciones locales, se ha decidido configurar los menús para que, a través del núcleo, pasen parámetros a las imágenes de disco RAM utilizadas. Estos parámetros se extraen en el programa linuxrc que toma control al cargarse el disco RAM y que, a su vez, hace uso de otros scripts que están en disco RAM:
Los clientes GNU/Linux utilizan el root.tgz para reconstruir su sistema de ficheros raíz. La gestión de este archivo se realiza mediante el script mkroot que utiliza tar para generar el fichero root.tgz.
La técnica utilizada se basa en generar el archivo partiendo de los directorios de una máquina con la distribución de Linux que queremos reproducir en el cliente y de una lista de archivos a excluir de entre todos ellos.
Luego a este archivo se le añaden o sustituyen los archivos que queramos, utilizando los que se almacenan en el directorio arranque_maquinas/client_root, que reproduce la jerarquía de directorios de un cliente.
Al final, el archivo root.tgz se distribuye a todos los binarios (desde el directorio arranque_maquinas/imagenes_rdist) ejecutando make rdist.
Para generar un root.tgz correspondiente a otra distribución, solamente habría que configurar algunos binarios con nueva distribución, generar a través de ellos una nueva imagen de reinstalación (otro fichero como el root.tgz pero con otro nombre), configurarlos para que diesen arranque a los clientes a través del menú de arranque y configurar el rc.local. Evidentemente, donde el administrador habría de emplear más tiempo sería en conocer la nueva distribución para que se adecue a los requisitos del laboratorio, modificando la lista de ficheros a excluir y los contenidos del directorio client_root.
Los pasos que debe seguir el administrador para soportar la instalación de una nueva distribución son:
En el caso de RedHat 7.3, los pasos aconsejados son (el siguiente proceso configurará el directorio /target/directory en el servidor):
1) Introducir el disco 1
2) mount /mnt/cdrom
3) cp -a /mnt/cdrom/RedHat /target/directory
4) umount /mnt/cdrom
5) Sustituir el disco 1 por el disco 2
6) mount /mnt/cdrom
7) cp -a /mnt/cdrom/RedHat /target/directory
8) umount /mnt/cdrom
9) Sustituir el disco 2 por el disco 3
10) mount /mnt/cdrom
11) cp -a /mnt/cdrom/RedHat /target/directory
12) umount /mnt/cdrom
El administrador tendrá que asegurarse de que el instalador de la nueva distribución no necesita parámetros que no estén contemplados. En caso de que sí los necesite, los deberá añadir como variables a la base de datos.
La herramienta utilizada para la creación de las imágenes de disco de Windows XP es partimage (38). Tiene interfaz de linea y también interfaz gráfico tipo menú, lo cual lo hace sencillo de manejar tanto en las fases de creación como en las de regeneración.
Las tareas de creación se han de realizar en el siguiente orden:
Cuando se dispone a añadir una máquina cliente del laboratorio, lo primero que debe hacer el operador es configurar la BIOS, llevando a cabo las siguientes tareas:
Habitualmente el fabricante de la tarjeta de red proporcionará un modo de grabar la ROM. El método más común es grabar a un disquete una imagen que contiene un ejecutable para hacerlo. Procedimiento:
Si por algún motivo (generación de nuevas imágenes de regeneración, instalación de aplicaciones, actualización o problemas con el sistema operativo) es necesario que se reinstalen los Windows XP del laboratorio, lo único que el operador debe hacer es:
Periódicamente, el servidor principal del laboratorio efectúa un chequeo de todos los servicios que tienen que estar funcionando en los servidores del laboratorio. Esto lo hace mediante la ejecución de diferentes comandos de nmap (58) y el posterior análisis de sus resultados. Tras efectuar las comprobaciones necesarias, envía un correo al operador(es) informando de la situación y, en caso de haber detectado algún fallo en el sistema, lo especifica en el correo electrónico para así agilizar la resolución del problema.
El modo de efectuar todas las comprobaciones necesarias, es mediante la ejecución de un script (lab_servers_info) a través del cron, que cada dos horas chequea puertos abiertos y espacio libre en los discos, entre otras cosas. El programa está situado en el directorio de servicios del usuario operador de la máquina maestro (maestro:/home/operador/administracion/servicios/lab_servers_info) y se puede ejecutar directamente cada vez que se quiera realizar esta tarea. Los resultados, se pueden observar en los ficheros de registro de actividad que se dejan en el directorio, o consultando el correo electrónico una vez que ha terminado el proceso.
Cuando el operador considere necesario, podrá efectuar una comprobación de qué clientes hay funcionando, a qué binarios están conectados, y qué sistema operativo están utilizando. Esta comprobación es, por supuesto, en tiempo real y se muestra directamente en el terminal de ejecución.
Disponer de esta información es necesario para hacer estadísticas de uso o en ocasiones en las que se necesite reiniciar un binario, para asegurar que no se queda sin servicio ningún cliente Linux del laboratorio. El programa se llama binarios_info y está situado en el directorio de servicios del usuario operador de la máquina maestro (maestro:/home/operador/administracion/servicios/binarios_info). Para obtener la información, sólo hay que ejecutarlo desde el directorio indicado (./binarios_info) y será mostrada en la misma consola del usuario.
Cuando el operador necesite comprobar las colas de impresoras desde el servidor maestro, podrá hacer uso de las herramientas estándar que se usan en GNU/Linux, dirigiendo la acción al servidor de impresoras (cuentas). Algunas de las operaciones que puede efectuar son:
ping impresoraA
ping impresoraB
ssh cuentas lpq -a
ssh cuentas lprm -PlpA <idTrabajo>
ssh cuentas lprm -PlpB <idTrabajo>
ssh cuentas lprm -PlpA -U<idUsuario>
ssh cuentas lprm -PlpB -U<idUsuario>
ssh cuentas lprm -PlpA all
ssh cuentas lprm -PlpB all
ssh cuentas /etc/init.d/lpd restart
Del mismo modo que el operador gestiona las colas de las impresoras, también puede gestionar la cola de correo electrónico. Algunas operaciones que puede efectuar son:
ssh cuentas mailq
ssh www mailq
ssh cuentas less /var/log/maillog
ssh www less /var/log/maillog
ssh cuentas /usr/sbin/sendmail -v -qR
ssh www /usr/sbin/sendmail -v -qR
Hecho ésto, el servidor comenzará a procesar de nuevo todos los mensajes almacenados en la cola, mostrando el registro de la conexión o el error que se produce si ésta no se puede establecer con el servidor remoto.
ssh cuentas /etc/init.d/sendmail restart
ssh www /etc/init.d/sendmail restart
Aunque no es parte del trabajo desarrollado por este proyecto, cabe mencionar, por ser una tarea propia de los laboratorios, que se ha preparado un modo de gestionar el alta en red de los clientes y servidores de forma que sea lo más sencillo y rápido posible. Tiene dos fases principales, una en el servidor central de administración del DIT y la otra en el servidor central de administración del laboratorio (maestro):
Dado que no nos interesa que GNU/Linux detecte la configuración del hardware de forma automática, hemos de tener en algún tipo de base de datos la información necesaria para configurarlo en cada cliente. El sistema de administración guarda esta información en un fichero de texto llamado clients_conf-1.1/lib/dispositivos, que está situado bajo el subdirectorio usrlocallocal del directorio de servicios del usuario operador en la máquina maestro (maestro:/home/operador/administracion/servicios/usrlocallocal).
Para realizar la configuración sólo habrá que cambiar o añadir el campo correspondiente del fichero y reiniciar el cliente. Un ejemplo de la línea de descripción del equipo l001, contenida en dispositivos se puede ver en la siguiente tabla, donde se indican (en este orden) el nombre de la máquina, la localización, el módulo utilizado para el ratón, el dispositivo del ratón, el tipo de tarjeta de vídeo y el tipo de monitor.
|
Este archivo se distribuye automáticamente y de forma periódica a los binarios a través del cron del sistema principal, pero si resulta necesario distribuirlo en un momento concreto se puede hacer mediante la orden make rdist en el mismo directorio.
En arranque, el cliente analiza la línea correspondiente a su nombre de máquina y elige la configuración preestablecida para cada uno de sus dispositivos, esta tarea se realiza a través del script /etc/rc.d/rc.local (véase el punto 6.2.2). El nombre de máquina, igual que el resto de los parámetros de red, el cliente los aprende a través del DHCP.
Se dispone de una aplicación específica para dar de alta o de baja usuarios, y efectuar algún cambio sobre las cuentas de dichos usuarios. Esta aplicación es labadmin. Su interfaz es a base de menús y el control se realiza a través de los cursores y la tecla [ENTER].
El caso de los laboratorios docentes del DIT tiene unas características particulares que impulsaron con mayor energía el desarrollo de este proyecto. Los puestos de laboratorio son ordenadores tipo PC, algunos de los cuales tienen instalado hardware adicional, con el fin de que sea posible la realización de prácticas especiales (normalmente de redes de datos y comunicaciones). En la tabla 7.2, se muestran las necesidades específicas de los laboratorios de grado y postgrado de los últimos años.
|
Además, los laboratorios docentes del DIT son utilizados también por otros grupos de alumnos de la ETSIT y cuyas necesidades se basan en el acceso a Internet y la utilización de los programas ofimáticos disponibles:
En la actualidad el laboratorio consta de 138 ordenadores de los que 137 están disponibles para los alumnos, el otro se utiliza para el acceso de profesores y personal de administración. Las estadísticas de acceso nos indican que en las fechas de máxima ocupación, se producen unas 700 entradas diarias al laboratorio (que también llamamos ``logins'') repartidas en los 680 turnos disponibles. Mensualmente, el número de logins viene a ser de unos 10000 aproximadamente (datos recogidos entre Marzo y Abril de 2003).
Todos estos datos, además de abrumar un tanto, permiten acotar perfectamente el entorno en el que nos movemos: aquel en el que el funcionamiento de los ordenadores, las redes y los servicios se ponen a prueba cada día y en el que la falta de disponibilidad de los mismos afecta a un gran número de personas. Como apunte, baste decir que el personal asignado para gestionar estos laboratorios es de 7 personas en la actualidad repartidas en dos turnos (mañana y tarde), lo que, comparado con el número de alumnos, e incluso con el número de ordenadores cliente, resulta en una desproporción considerable. Más aún, si consideramos que también han de gestionar los servidores, los servicios y las redes que interconectan unos y otros, cabe considerar que de no haberse realizado el diseño e implantación de este sistema de administración centralizada no habría sido posible dar servicio con una calidad razonable a la cantidad de usuarios de los laboratorios del DIT.
La idea desarrollada pretende dar la máxima independencia al alumno que utiliza los puestos de laboratorio del DIT. La única forma de hacerlo es asegurándonos de que, siempre que lo necesite, podrá partir de un sistema conocido y estable, a partir del cual será capaz de realizar las tareas encomendadas en las prácticas. Nosotros hemos implementado esta solución basándonos en la regeneración o la instalación del puesto de laboratorio desde los servidores de arranque de la red local del mismo, dándole prioridad al rendimiento y usabilidad del método.
Dada la aplicación del laboratorio a la docencia sobre redes y servicios telemáticos, se ha creado una gran infraestructura hardware que implica la asignación a cada ordenador del laboratorio de infraestructura para tres redes independientes por lo menos, mediante cable de par trenzado. Esto genera un volumen de trabajo de instalación y mantenimiento nada despreciable.
El esquema arquitectónico permite jerarquizar las funciones que puede realizar el operador (tareas rutinarias y de bajo coste) que llamamos tareas de frontend, mientras que por debajo están las tareas de administración que son realizadas por administradores altamente cualificados y son tareas de alto coste agrupables en el concepto backend.
En cuanto a los tiempos de regeneración de los puestos de laboratorio, las pruebas realizadas demuestran que se puede instalar un cliente GNU/Linux en menos de 2 minutos, a partir del segundo arranque del sistema (en el primer arranque se guardaría la imagen en la caché ubicada en una de las particiones del disco duro). Para regenerar un cliente de Windows XP se puede tardar alrededor de 5 minutos en la regeneración de la partición NTFS (si el archivo de la imagen ya está almacenado en la caché local), tardando en torno a 10 minutos el proceso de autoconfiguración posterior al reinicio.
La instalación de un servidor GNU/Linux de los que sirven como secundarios de arranque (también llamados en este texto binarios) viene a tardar en torno a 10 minutos la instalación del mismo, mientras que el proceso de reconfiguración posterior (autoactualiza) viene a tardar otros 10 minutos, en función del tamaño de las imágenes que el servidor maestro le tenga que distribuir.
La instalación de un servidor Windows XP estándar con el procedimiento de instalación por red de Microsoft, viene a durar unos 40 minutos, mientras que el proceso posterior al reinicio utilizado para instalarle las aplicaciones puede tardar unos 20 minutos más. Este proceso es el más largo de todos, debido a que es básicamente lo que se tardaría en una instalación manual si no fuese necesario que interviniese el administrador para responder a ninguna pregunta de forma interactiva.
La red de producción del DIT da servicio a más de 170 usuarios estables (entre profesores, personal de administración, doctorandos, becarios y colaboradores), aunque dentro del departamento, se administran más de 370 cuentas de usuario. La red de producción se caracteriza por ser de carácter estable y ofrecer a través de ella los servicios necesarios para la gestión de la información tanto interna como externa. En ella, se utilizan más de 700 direcciones IPv4, sin contar de los laboratorios docentes.
Si tenemos en cuenta que -como media- habrá un reparto de 0.75 ordenadores de uso personal por cuenta, habrá cerca de 280 ordenadores de tipo cliente en el departamento, que son en su gran mayoría instalados, mantenidos, administrados y actualizados por cada uno de los usuarios del departamento.
Muchas veces, debido a las necesidades particulares de cada usuario, este tipo de gestión resulta lo más conveniente, pero está claro que implica una gran inversión de tiempo de cada uno de ellos para la realización de tareas que no aportan valor a su trabajo, lo que convierte claramente este tipo de tareas en candidatas a ser realizadas centralizadamente.
En este tipo de red, tradicionalmente las tareas de administración se han concentrado en dar los llamados servicios comunes a los usuarios, como pueden ser:
Otro factor que nos impulsa a generalizar el uso de la administración centralizada es el aumento vertiginoso del número de PCs (tanto portátiles como de oficina) en los últimos años, consecuencia del abaratamiento de costes y del gran número de capacidades de que disponen. A esto se ha unido el progresivo aumento en la utilización de sistemas operativos de tipo servidor, lo que ha obligado a una mayor necesidad de conocimientos y de consejo en las tareas de administración, ya que no están específicamente orientados al usuario ofimático.
Por todo ello, desde el año 2002, se están aplicando los conocimientos desarrollados a través del sistema de gestión centralizada de los laboratorios docentes para instalar y administrar también los de la red de producción, estando actualmente integrados en él más de 10 servidores GNU/Linux. También se ha realizado ya la instalación de más de 10 ordenadores personales con sistema operativo Windows XP de forma automática y desatendida, estando en fase de depuración y perfeccionamiento para permitir al usuario realizar el proceso por sí mismo sin intervención del Centro de Cálculo.
Analizaremos en esta sección el grado de cumplimiento de los objetivos planteados para este proyecto.
La reinstalación de servidores mediante el sistema de administración centralizada, en comparación con lo anterior, es mucho más lento debido a la propia naturaleza secuencial y el alto consumo de CPU en las tareas de descompresión de archivos y transferencia a disco, pero también hay que decir que es mucho más rápida por ser desatendida y estar totalmente automatizada.
Aunque en esta versión del sistema de gestión no se han incluido mecanismos de distribución multicast de archivos, la utilización de cachés de disco ha permitido minimizar la utilización de la red para las tareas de regeneración y reinstalación de clientes, con lo que la rapidez es máxima en la mayoría de los casos. Podemos por tanto dar por cumplido este objetivo.
Se mencionan a continuación los beneficios que ha proporcionado nuestro sistema fuera de sus objetivos principales.
Hay varias cosas que se han planteado para realizar en un futuro y ampliar la capacidad, gestionabilidad e inteligencia del sistema de administración centralizada. Se mencionan a continuación por orden de importancia, especificando brevemente ciertos detalles posibles de su implementación.
En este entorno, también parece necesaria la implantación de una política de seguridad que permita controlar no sólo la integridad del software instalado en servidores y clientes, sino también otros parámetros de seguridad relativos a las restricciones de acceso a los mismos y a la administración de los datos privados de los usuarios con respecto a la normativa vigente en cada caso.
Pliego de condiciones
Presupuesto
Este proyecto se ha desarrollado dentro del Centro de Cálculo del Departamento de Ingeniería de Sistemas Telemáticos de la Universidad Politécnica de Madrid.
A continuación se dividen los costes de ejecución material en costes de equipamiento (o costes materiales) y costes de mano de obra.
El Centro de Cálculo del DIT cuenta ya con una serie de instalaciones y equipos que han sido suficientes para la implementación de la arquitectura del sistema de administración centralizada y la realización de las diferentes pruebas de funcionamiento del mismo. Para la valoración del equipamiento utilizado se han considerado diferentes porcentajes según la utilización del equipamiento en funciones correspondientes a este proyecto. Esos porcentajes han sido introducidos en el presupuesto de este proyecto para calcular la influencia del mismo en la inversión total realizada. También se incluyen como costes generales el suministro eléctrico, el material fungible y el gasto en comunicaciones.
En las siguientes tablas de coste se desglosan los costes por equipo.
|
| ||||||||||||||||||||||||
En el proyecto ha intervenido un Ingeniero Superior de Telecomunicación que es el que se ha encargado del desarrollo de las diferentes tareas que engloba. En la siguiente tabla se encuentra un desglose de tareas y la duración estimada de las mismas en horas de trabajo.
|
Multiplicando por el sueldo por hora de un Ingeniero, se obtiene el coste total de la mano de obra.
|
Se consideran gastos generales las amortizaciones, las cargas fiscales y jurídicas y gastos de instalación, que se valoran en el 15% del presupuesto de ejecución material.
|
El presupuesto total del proyecto alcanza la cifra de CUARENTA Y CUATRO MIL OCHOCIENTOS TREINTA Y UN EUROS CON TREINTA Y TRES CÉNTIMOS.
This document was generated using the LaTeX2HTML translator Version 2002 (1.62)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -no_subdir -split 0 -show_section_numbers ../Proyecto_Omar/Proyecto_Omar.tex
The translation was initiated by root on 2003-07-25
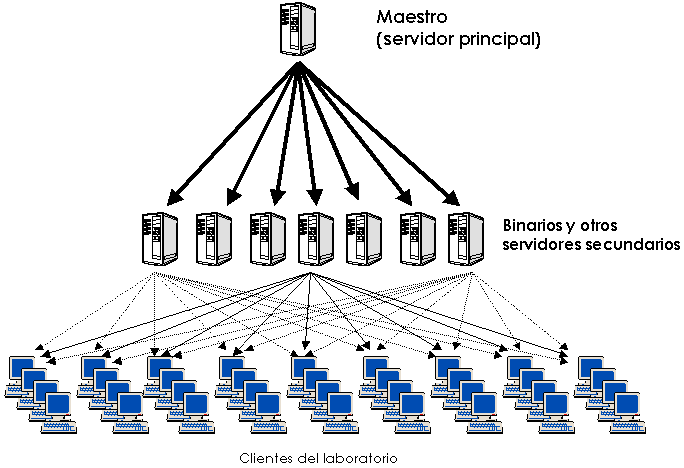


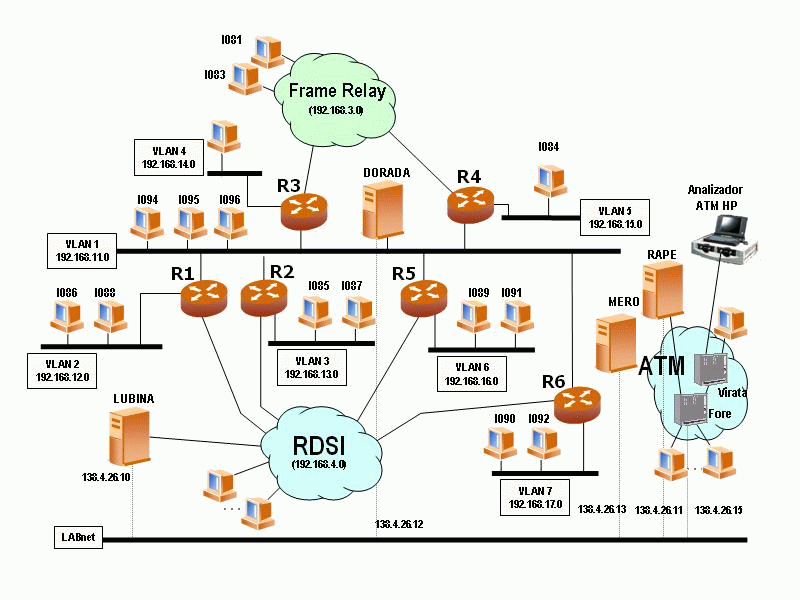
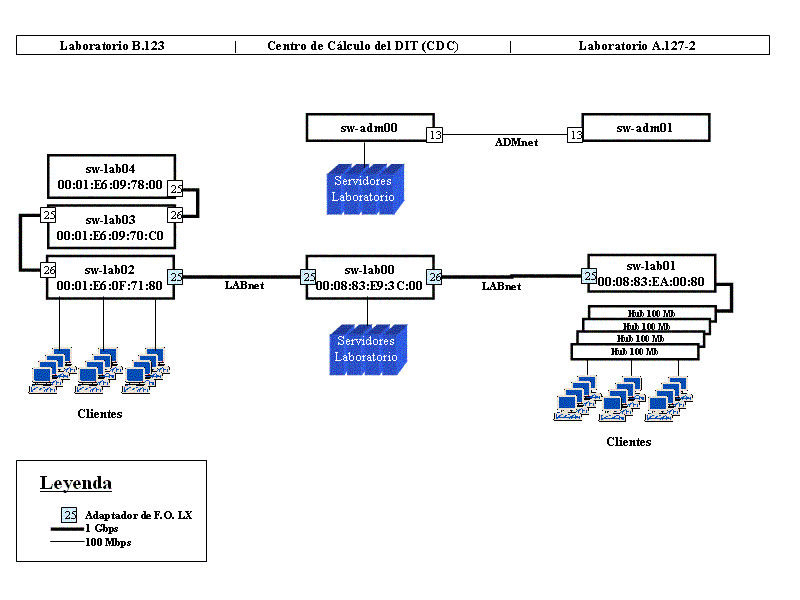

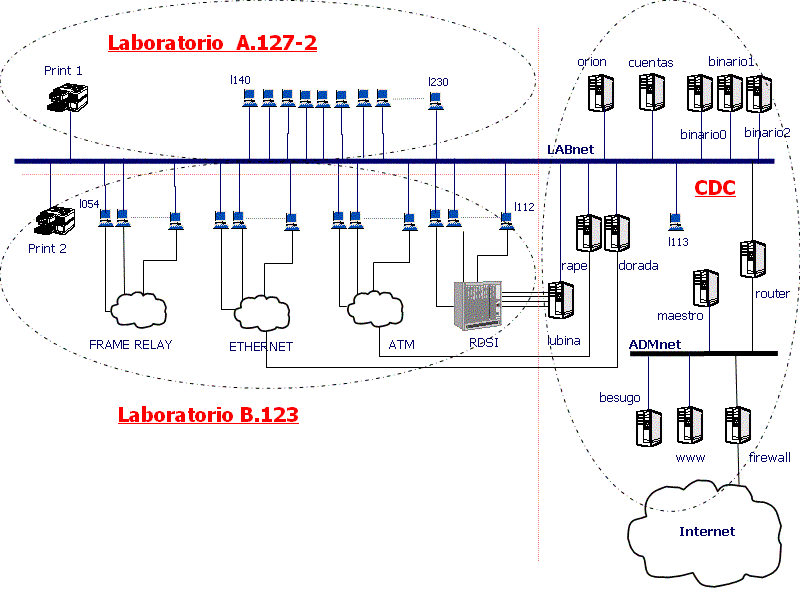

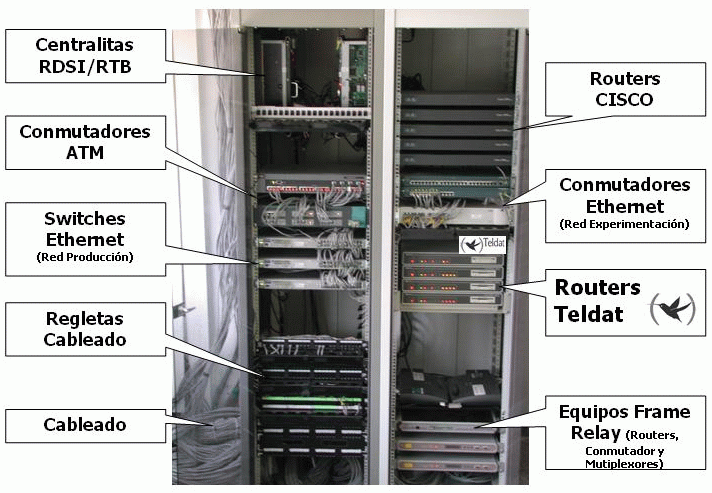
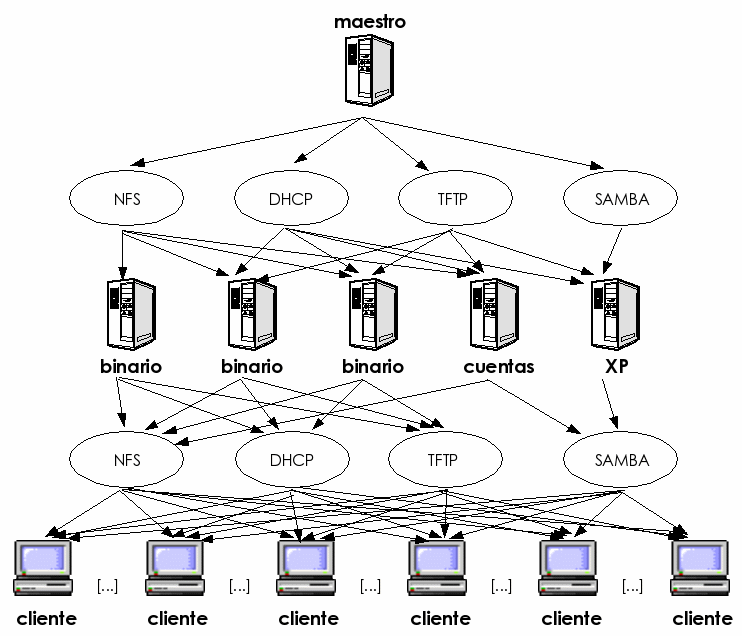
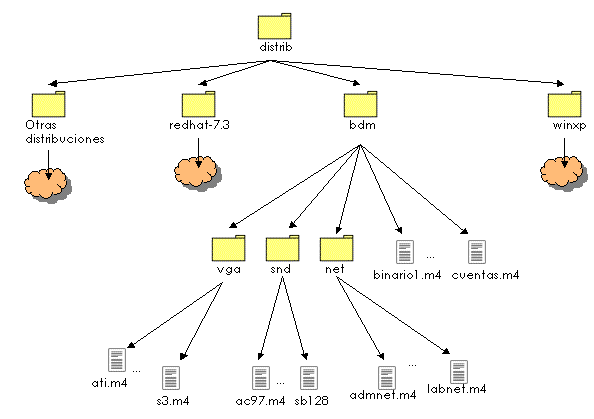
![\begin{figure}\begin{center}\begin{tabular}{\vert l\vert}
\hline
\texttt{includ...
...xttt{{[}...{]}}\tabularnewline
\hline
\end{tabular}\end{center}\par\end{figure}](img4.png)